Blog
EU AI Act & DSGVO für Entwicklerteams: Welche KI-Coding-Tools dürfen wir wirklich einsetzen?
Kurz und scharf
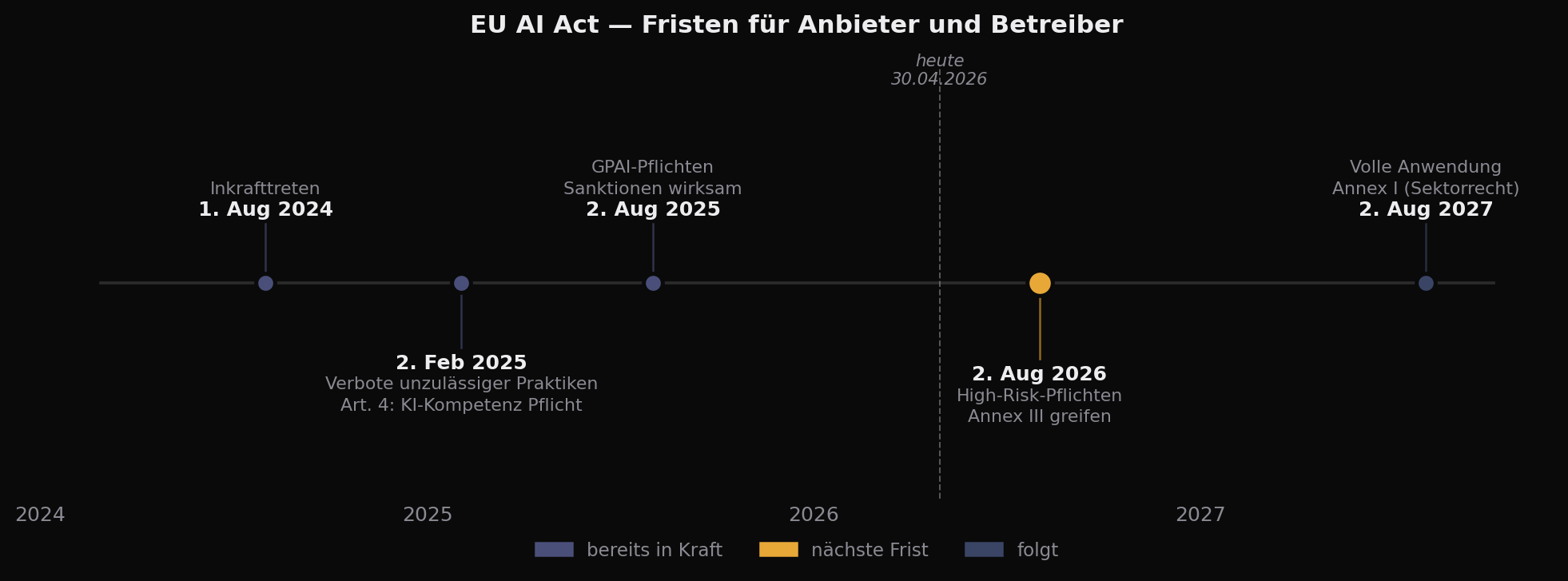
Der EU AI Act trifft Entwicklerteams nicht über die Tools selbst, sondern über die Rolle, in der man sie einsetzt. KI-Coding-Tools wie GitHub Copilot, Cursor AI und Claude Code sind grundsätzlich keine Hochrisiko-Systeme — gefährlich wird es erst, wenn der erzeugte Code in ein Hochrisiko-System fließt. DSGVO-konform sind diese Tools nur in den kommerziellen Tarifen mit Auftragsverarbeitungsvertrag, ausgeschlossenem Modell-Training und sauberem Drittlandtransfer. Am 2. August 2026 greifen die High-Risk-Pflichten — bis dahin sollte jedes Team eine schriftliche Tool-Policy, eine KI-Kompetenz-Schulung und einen klaren Anbieter-vs-Betreiber-Status haben.
Im März saß ich mit dem Head of Engineering eines Mittelständlers zusammen, dessen Datenschutzbeauftragter ihm gerade per E-Mail die Nutzung von GitHub Copilot untersagt hatte. Die Begründung: "Wir wissen nicht, was mit dem Code passiert." Das Team arbeitete seit über einem Jahr produktiv mit Copilot Business, hatte einen Auftragsverarbeitungsvertrag in der Schublade, das Privacy-Setting korrekt konfiguriert — und stand jetzt vor der Frage, ob jemand das Verbot tatsächlich rechtlich begründen kann oder ob es ein reflexhaftes Vorsichtsurteil war. Es war eindeutig das zweite. Genau deshalb lohnt sich dieser Artikel: nicht weil KI-Coding-Tools im Unternehmen pauschal verboten oder erlaubt wären, sondern weil die meisten Verbote auf Halbwissen beruhen und die meisten Freigaben auf Optimismus.
Wir sind am 30. April 2026. In genau drei Monaten greifen die Pflichten des EU AI Act für Hochrisiko-Systeme nach Annex III. Die KI-Kompetenz-Pflicht nach Artikel 4 ist seit über einem Jahr in Kraft, viele Teams haben sie noch nicht einmal gelesen. Die DSGVO gilt sowieso, seit acht Jahren. Was sich verändert hat: Es gibt zum ersten Mal eine spezialisierte KI-Verordnung, die Entwicklerpflichten konkret benennt. Wer in dieser Lage immer noch davon ausgeht, dass "die IT das schon regelt", hat den Stand verpasst.
Anbieter, Betreiber und der zentrale Rollenirrtum
Die wichtigste Unterscheidung im AI Act ist die zwischen Anbieter und Betreiber. Anbieter sind die, die ein KI-System auf den Markt bringen oder unter eigenem Namen einsetzen — bei den meisten Coding-Tools sind das die Hersteller: GitHub, Cursor, Anthropic. Betreiber sind die, die ein bereits existierendes System professionell nutzen — also wir, die Entwicklerteams. Diese Unterscheidung klingt banal, ist aber rechtlich der entscheidende Hebel. Anbieter haben ein Vielfaches an Pflichten, von der Konformitätsbewertung über die technische Dokumentation bis zur Risikomanagementsystem-Architektur. Betreiber haben deutlich weniger — und genau hier wird es im Beratungsalltag interessant.
Der Rollenirrtum, den ich am häufigsten sehe, ist die Annahme, dass jedes Unternehmen, das ein KI-Tool einsetzt, automatisch in der Anbieterrolle landet. Das stimmt nicht. Solange ein Team Copilot oder Cursor "out of the box" verwendet, ohne das Modell zu trainieren oder unter eigenem Markennamen auszurollen, bleibt es Betreiber. Das ändert sich erst, wenn das Tool wesentlich modifiziert wird — etwa durch eigenes Fine-Tuning auf Firmencode mit anschließender Bereitstellung an Endkunden. Dann kippt die Rolle, und mit ihr die Pflichtenlast. Wer also die Entscheidung trifft, intern ein Custom-Modell auf seine Codebase zu trainieren und Kunden Zugriff darauf zu geben, sollte vorher mit der Rechtsabteilung sprechen, nicht danach.
Diese Anbieter-vs-Betreiber-Frage entscheidet auch, wie schwer die DSGVO-Last wiegt. Als Betreiber schließt man einen Auftragsverarbeitungsvertrag mit dem Anbieter und ist damit weitgehend in der Verantwortung des Auftraggebers — der Anbieter trägt die schwere Compliance. Als Anbieter wird man selbst zum datenverarbeitenden Verantwortlichen für alles, was die eigenen Modelle berühren. Das ist ein dramatischer Unterschied, der oft übersehen wird, wenn ein Team euphorisch beschließt, "ein eigenes Coding-LLM" zu bauen.
Fällt GitHub Copilot unter den AI Act?
Ja, aber nicht so, wie viele befürchten. Copilot ist ein KI-System im Sinne der Verordnung und nutzt General-Purpose-AI-Modelle, für die seit August 2025 eigene Pflichten gelten. Diese Pflichten treffen aber GitHub und OpenAI als Modellanbieter, nicht das einsetzende Unternehmen. Für die Hochrisiko-Klassifikation nach Annex III gibt es keinen Eintrag, der "KI für Code-Generierung" als Hochrisiko einstuft. Code zu schreiben ist nicht per se gefährlich — gefährlich wird es erst, wenn dieser Code in einem System landet, das selbst hochriskant ist.
Die intuitiv naheliegende Sorge, dass Copilot durch die Hintertür unter strengste Aufsicht fallen könnte, lässt sich also entkräften. Das Tool selbst trägt seine Pflichten beim Anbieter. Was bei den Betreibern bleibt, sind die allgemeinen Vorschriften: KI-Kompetenz, Transparenz gegenüber den eigenen Mitarbeitern, sinnvolle menschliche Aufsicht. Wer Copilot in einer Bank, einer Klinik oder einem Energieversorger einsetzt, muss eine Klasse höher denken — dazu unten mehr.
GitHub Copilot DSGVO und der Tarif-Unterschied, der alles entscheidet
Wer GitHub Copilot DSGVO-konform einsetzen will, muss zuerst auf den Tarif schauen. Copilot Free und Copilot Pro sind Consumer-Produkte. Die dortigen Standardeinstellungen erlauben GitHub bis zu einem gewissen Grad, Telemetrie und in Einzelfällen Code-Snippets für Modellverbesserungen zu nutzen. Es gibt Opt-Out-Schalter, aber keinen verbindlichen Vertrag, der das fest verankert. Für ein Unternehmen, das echte Codebases mit echten Geschäftsgeheimnissen schützen will, ist das nicht ausreichend.
Copilot Business und Copilot Enterprise sind eine andere Welt. Beide Tarife schließen vertraglich aus, dass Prompts oder Suggestions für das Modelltraining genutzt werden. Beide bieten einen Auftragsverarbeitungsvertrag (das sogenannte Data Processing Addendum), der die DSGVO-Pflichten zwischen GitHub als Auftragsverarbeiter und dem Unternehmen als Verantwortlichem sauber regelt. Beide stützen den Drittlandtransfer in die USA über das EU-US Data Privacy Framework, in das GitHub Inc. eingetragen ist. Damit fällt für Standardanwendungen die Notwendigkeit weg, eigene Standardvertragsklauseln zu verhandeln. Das ist keine Lappalie, sondern erspart Unternehmen monatelange juristische Detailarbeit.
Der Unterschied zwischen Business und Enterprise ist im Datenschutzkontext überschaubar. Enterprise bringt zusätzlich SAML-SSO, granularere Audit-Logs und IP-Indemnification — aber die DSGVO-Substanz ist die gleiche. Wer ein kleineres Team ausstattet, ist mit Business gut bedient. Wer eine Konzern-Compliance bedienen muss, profitiert von Enterprise wegen der Audit-Tiefe. Was beide Tarife nicht leisten: garantierte EU-Datenresidenz für die Modell-Inferenz. Wer das wirklich braucht, sollte die Frage explizit mit dem Account Manager klären — GitHub baut Enterprise-Hosting-Optionen aus, aber der Stand wechselt.
Ist Cursor AI DSGVO-konform?
Cursor ist anders gebaut als Copilot, und das macht die DSGVO-Bewertung interessanter. Cursor selbst hostet keine Modelle, sondern routet die Anfragen an Anthropic, OpenAI, Google oder neuerdings auch an die eigenen Cursor-Modelle. Das heißt, in jedem Cursor-Setup steht mindestens ein Sub-Processor zwischen Cursor und dem letztendlich antwortenden Modell. Das ist datenschutzrechtlich nicht problematisch, aber dokumentationspflichtig.
Damit Cursor AI DSGVO-konform betrieben werden kann, sind drei Stellschrauben relevant. Erstens der Privacy Mode, der in Pro- und Business-Tarifen aktivierbar ist und sicherstellt, dass weder Code noch Prompts persistent bei Cursor oder den Modellanbietern gespeichert werden — und nicht für Training genutzt werden. Zweitens das Auftragsverarbeitungsvertrags-Setup mit Cursor, das die nachgelagerten Sub-Processor mit abdeckt. Drittens die ausdrückliche Auswahl, welche Modelle verwendet werden dürfen. Wer als Team beschließt, ausschließlich Anthropic-Modelle zu nutzen, hat eine andere Risikolandschaft als ein Team, das wahllos zwischen sechs Anbietern wechselt.
Was bei Cursor in der Praxis oft vernachlässigt wird, ist das Codebase-Indexing. Cursor erstellt Embeddings der lokalen Codebase, um relevanten Kontext in Prompts einzuspeisen. Diese Embeddings werden auf Cursor-Servern gespeichert. Im Privacy Mode geschieht das verschlüsselt und kurzlebig, aber es ist eine Datenverarbeitung, die im Verzeichnis nach Artikel 30 DSGVO auftauchen muss. Wer ein Repository mit personenbezogenen Daten in Test-Fixtures hat, sollte vor der Cursor-Einführung aufräumen — das ist sowieso überfällig, aber jetzt mit konkretem Anlass.
Was muss ich beim Einsatz von Claude Code beachten?
Claude Code ist im engeren Sinne kein Tool im klassischen Sinn, sondern ein Terminal-Agent, der gegen die Anthropic-API arbeitet. Diese Architektur hat datenschutzrechtlich angenehme Eigenschaften und einen unangenehmen Zusatzpunkt. Angenehm: Anthropic ist DPF-zertifiziert (das Unternehmen taucht in der offiziellen Liste des Data Privacy Framework auf), bietet einen Auftragsverarbeitungsvertrag und garantiert in den kommerziellen Tarifen ausdrücklich, dass Inputs nicht zum Modelltraining verwendet werden. Das ist seit März 2024 vertraglich fix und gilt unabhängig vom Tier. Wer noch mehr Sicherheit braucht, kann eine Zero-Data-Retention-Vereinbarung im Enterprise-Vertrag aushandeln, die das vollständige Vorhalten von Prompts und Outputs technisch unterbindet — ein Mechanismus, den vor allem Banken und Versicherungen in Anspruch nehmen.
Der unangenehme Punkt: Claude Code liest und schreibt lokale Dateien. Anders als Copilot, das nur Vorschläge macht, agiert Claude Code als Agent, der Tools aufruft und Dateien modifiziert. Das verändert die Risikobewertung, weil die menschliche Aufsicht nicht mehr beim Akzeptieren eines einzelnen Vorschlags stattfinden kann, sondern erst beim Code-Review der Pull Requests. In Workflows, in denen Claude Code in CI-Pipelines läuft oder ohne Review committen darf, fehlt diese Aufsicht — und dann reden wir über eine ernste Lücke gegenüber Artikel 14 AI Act, der für Hochrisiko-Systeme menschliche Aufsicht fordert. Auch wenn Claude Code selbst nicht hochriskant ist, sollte man die Aufsichtslogik aus dem AI Act als Best-Practice-Maß übernehmen. Ich habe noch keinen Datenschutzbeauftragten gesehen, der einen Agent ohne Review-Pflicht abgenickt hat, und ich erwarte auch keinen.
Für die DSGVO-Sicht beim Claude Code Datenschutz im Unternehmen ergibt sich ein klares Bild: API-Schlüssel zentral verwalten, kommerzieller Tarif mit Anthropic-AVV, Privacy-Optionen aktivieren, klare Regeln, welche Repositories und welche Datenklassen mit Claude Code bearbeitet werden dürfen. Bei sicherheitskritischer Software bleibt der Agent außen vor — nicht weil er es nicht könnte, sondern weil die Audit-Last für jede Datei-Änderung im Prozessmodell schwer abbildbar ist.
Welche Pflichten habe ich nach dem EU AI Act als Entwickler?
Die KI-Verordnung adressiert Entwicklerpflichten differenzierter als oft dargestellt. In den meisten Konstellationen ist ein Entwicklerteam ein Betreiber, das ein KI-System einsetzt — kein Anbieter. Daraus ergibt sich eine überschaubare, aber nicht triviale Pflichtenliste, die sich auf vier Punkte verdichten lässt.
Erstens die KI-Kompetenz-Pflicht aus Artikel 4. Sie gilt seit dem 2. Februar 2025 und verlangt, dass Mitarbeiter, die KI-Systeme bedienen, ein "ausreichendes Verständnis" davon haben. Was das genau heißt, hat der Gesetzgeber bewusst offen gelassen, um den unterschiedlichen Kontexten Rechnung zu tragen. Für Entwicklerteams hat sich in der Praxis ein dokumentierter Schulungspfad bewährt: Grundlagen zu Modellen, zu Prompt-Mechanik, zu Halluzinationsrisiken, zur Tool-spezifischen Datenverarbeitung. Eine Stunde reicht nicht, drei Tage sind übertrieben — ein halber bis ganzer Tag mit nachgelagerter Selbstlernphase trifft den Punkt. Wichtig ist die Dokumentation: Teilnehmerlisten, Inhalte, Datum. Ohne diese Belege ist die Pflicht im Audit nicht nachweisbar.
Zweitens die menschliche Aufsicht. Sie ist im AI Act explizit nur für Hochrisiko-Systeme gefordert (Artikel 14), aber als Standard auch für nicht-hochriskante Tools sinnvoll. Im Entwicklerkontext heißt menschliche Aufsicht: KI-generierter Code geht durch einen Pull-Request-Review eines erfahrenen Entwicklers, bevor er in Main landet. Klingt selbstverständlich, ist es aber in vielen Teams nicht — gerade Solo-Developer und kleine Teams haben oft keine echte Review-Pflicht etabliert. Ohne sie wird der KI-Coding-Tool-Einsatz schwer verteidigbar.
Drittens die Transparenzpflicht gegenüber den eigenen Mitarbeitern. Wenn das Unternehmen KI-Tools im Arbeitsalltag einsetzt, ist das mitbestimmungspflichtig — § 87 Absatz 1 Nummer 6 BetrVG, "Einführung und Anwendung von technischen Einrichtungen, die dazu bestimmt sind, das Verhalten oder die Leistung der Arbeitnehmer zu überwachen". KI-Coding-Tools fallen unter diese Vorschrift, weil sie Telemetriedaten erheben können, auch wenn sie nicht zur Leistungskontrolle eingesetzt werden. Eine Betriebsvereinbarung lohnt sich, wo ein Betriebsrat existiert. Wo keiner existiert, sollte zumindest eine schriftliche Information an alle betroffenen Mitarbeiter ergehen.
Viertens, falls personenbezogene Daten ins Spiel kommen, eine Datenschutz-Folgenabschätzung nach Artikel 35 DSGVO. Im typischen Coding-Alltag ist das nicht der Fall, weil Quellcode meistens keine personenbezogenen Daten enthält. Sobald aber Test-Fixtures echte Kundendaten enthalten oder Prompts mit Auszügen aus produktiven Datenbanken arbeiten, kippt die Lage. Hier hilft eine simple Regel: Was nicht in einen externen Slack-Thread gehört, gehört auch nicht in einen LLM-Prompt.
Wenn der Code in ein Hochrisiko-System fließt
Die Frage, ob ein KI-Coding-Tool unter die High-Risk-Kategorie fällt, wird oft falsch gestellt. Das Tool selbst ist nicht hochriskant — der Kontext, in dem der erzeugte Code eingesetzt wird, kann es sein. Annex III des AI Act listet konkrete Anwendungsfelder auf, in denen KI-Systeme als hochriskant gelten: kritische Infrastrukturen, Bildung, Beschäftigung, Strafverfolgung, Migration, Justiz und einige weitere. Annex I verweist auf Sektorrecht — Medizinprodukte, Maschinenrichtlinie, Fahrzeugzulassung. Software, die in solche Systeme eingebaut wird, fällt unter die spezifischen Pflichten dieser Sektoren plus die AI-Act-Pflichten für die KI-Komponenten.
Was das für die Entwicklungsphase heißt, wird selten klar ausgesprochen. Wenn ein Team Software für ein Medizingerät schreibt und dabei Copilot einsetzt, ist Copilot weiterhin nicht hochriskant. Aber das entstehende Medizingerät ist es, und die Anforderungen der IEC 62304 plus AI Act greifen für den Code, den dieses Tool produziert. Praktisch heißt das: die Code-Reviews werden tiefer, die Test-Coverage muss höher sein, die Traceability-Pflichten der Sektorrichtlinie gelten weiter, und wer KI-generierten Code in solche Systeme einsetzt, sollte das in der Risk-Analyse abbilden — mit klarer Kennzeichnung, welche Module KI-unterstützt erstellt wurden, und welche Review-Schritte sie durchlaufen haben.
Diese Anforderung wird gern unterschätzt, weil sie nicht im AI Act selbst steht, sondern aus der Verbindung mit dem Sektorrecht entsteht. Ein Bauteil-Hersteller, der Maschinensteuerungen entwickelt, hat seit Jahren Prozesse für Code-Audits — die müssen jetzt um den KI-Faktor erweitert werden. Das ist machbar, aber nicht trivial, und es ist ein häufiger Anlass, warum Teams in regulierten Branchen zögern, KI-Coding-Tools breit einzuführen. Mein Rat in diesen Fällen: nicht warten, sondern strukturiert in nicht-kritischen Modulen anfangen, dort den Review-Prozess härten und dann schrittweise ausweiten. Wer auf das perfekte Audit-Setup wartet, wartet zwei Jahre und hat in der Zwischenzeit den Anschluss verloren.
Code, Prompts und Personenbezug — was die DSGVO wirklich verlangt
Die rechtliche Behandlung von Code-Prompt-Datenverarbeitung unter der DSGVO ist trockener Stoff, aber unausweichlich. Quellcode ist im Regelfall kein personenbezogenes Datum. Eine Klasse, eine Funktion, eine Schnittstellendefinition enthält keinen Personenbezug. Sobald aber Kommentare echte Namen enthalten, Commit-Histories Personenbezug aufbauen oder Test-Daten reale Datensätze sind, kippt die Lage. Genau das ist der Standardfall in vielen Repositories.
Praktisch heißt das: Vor dem Rollout eines KI-Coding-Tools lohnt sich eine ehrliche Bestandsaufnahme der eigenen Codebase. Welche Repositories enthalten Test-Daten mit echten Kundendaten? Wo finden sich Logfiles oder Datenbank-Dumps in der Repo-Historie? Welche Konfigurationsdateien haben Klarnamen? Diese Bestandsaufnahme ist sowieso überfällig — Datenschutz fängt bei der eigenen Disziplin an, nicht beim Cloud-Anbieter. Aber jetzt gibt es einen konkreten Anlass.
Wenn nach der Bestandsaufnahme Personenbezug bleibt und sich nicht entfernen lässt, ist die Verarbeitung nach DSGVO begründungspflichtig. Die typische Rechtsgrundlage ist Artikel 6 Absatz 1 Buchstabe f — berechtigtes Interesse. Es ist legitim, dass ein Unternehmen seine Entwicklungsprozesse mit modernen Werkzeugen unterstützt. Diese Begründung muss aber dokumentiert sein, und eine Interessenabwägung muss vorliegen. Wer sich diese Mühe spart, hat im Audit ein Problem.
Welche KI-Coding-Tools sind DSGVO-konform — eine pragmatische Antwort
Die ehrliche Antwort lautet: Es gibt keine pauschale Aussage. Jedes Tool kann DSGVO-konform betrieben werden, wenn die Vertragslage stimmt, der Tarif passt und die internen Prozesse funktionieren. Jedes Tool kann auch in der DSGVO-Verletzung enden, wenn Free-Versionen ohne Vertrag genutzt werden, sensible Daten in Prompts landen oder Mitarbeiter ohne Schulung loslegen. Entscheidend ist also weniger das Tool als das Setup darum.
Trotzdem hier eine kurze pragmatische Einordnung der drei Marktführer, die ich in Trainings am häufigsten sehe. GitHub Copilot Business und Enterprise sind für Standardanwendungen die robusteste Wahl, weil GitHub seit Jahren auf Enterprise-Compliance optimiert. Cursor ist im Privacy Mode mit Business-Tarif eine valide Option, vor allem für Teams, die Modell-Flexibilität wollen — die Sub-Processor-Komplexität ist allerdings höher. Claude Code lohnt sich für Teams, die agentisches Arbeiten produktiv machen wollen und bereit sind, einen klaren Review-Prozess auf Pull-Request-Ebene zu etablieren — die DSGVO-Substanz von Anthropic ist solide.
Was in keinem dieser drei Tools im Unternehmenseinsatz Platz hat, sind die Free- oder Consumer-Tarife. Der Verlockung, "erstmal mit dem Gratis-Plan zu starten und später hochzuziehen", widerstehen die Compliance-Verantwortlichen aus gutem Grund. Die Datenflüsse in Free-Tarifen sind nicht kontrolliert genug, und ein nachträglicher Wechsel löst die Frage nicht, was in der Zwischenzeit alles in Trainingsdaten gelandet sein könnte.
Was Teams im Mai und Juni konkret entscheiden müssen
Drei Monate vor der nächsten AI-Act-Frist ist der richtige Zeitpunkt, um die offenen Punkte zu schließen. Aus meiner Beratungspraxis kristallisiert sich eine Reihenfolge, die in den meisten Unternehmen funktioniert. Sie ist keine Pflicht, sondern eine Pragmatik.
Anfangen sollte man mit der Klärung der Rolle: Sind wir Betreiber oder Anbieter? Diese Frage entscheidet die Pflichtenlast. In der Regel ist die Antwort "Betreiber", aber der Schritt, das schriftlich festzuhalten und mit der Rechtsabteilung abzustimmen, ist nicht trivial. Anschließend kommt das Tool-Inventar: Welche KI-Tools werden tatsächlich im Team genutzt, in welchen Tarifen, mit welchen Verträgen? Shadow AI ist in vielen Unternehmen die größere Baustelle als die offiziellen Tools, und genau hier blühen die Probleme. Die Bestandsaufnahme dauert eine bis zwei Wochen, deckt aber meist Überraschendes auf — vom privaten ChatGPT-Account, der Quellcode-Snippets sieht, bis zum Cursor-Privatabo eines Senior Devs, der "schon immer so gearbeitet hat".
Im zweiten Schritt kommt die Vertragsarbeit: AVV mit den Anbietern abschließen, DPF-Zertifizierung prüfen, Sub-Processor-Listen reviewen, im Zweifel Standardvertragsklauseln nachziehen. Parallel dazu die Schulung — ein dokumentierter Trainings-Tag pro Team, der die Tools vorstellt, die Datenflüsse erklärt und die internen Regeln festigt. Der Trainings-Tag ist auch das Vehikel, das die KI-Kompetenz-Pflicht aus Artikel 4 erfüllbar macht.
Im dritten Schritt schreibt jemand die interne KI-Coding-Tool-Compliance-Richtlinie. Eine Seite, klare Sprache, drei Abschnitte: erlaubte Tools mit Tarif-Pflicht, verbotene Inhalte in Prompts (personenbezogene Daten, Geheimnisse, Lizenz-kritische Codes), Review-Pflicht für KI-generierten Code. Diese Richtlinie wandert ans Schwarze Brett, ins Onboarding und in die jährliche Auffrischung. Wer drei Monate hat, kann das alles schaffen — wer wartet, bis die Aufsicht fragt, hat schon verloren.
Häufige Fragen
Darf ich GitHub Copilot im Unternehmen nutzen?
Ja, in der Business- oder Enterprise-Variante. Diese Tarife schließen vertraglich aus, dass Code oder Prompts zum Training der zugrundeliegenden Modelle verwendet werden, bieten einen Auftragsverarbeitungsvertrag und stützen den Drittlandtransfer in die USA über das EU-US Data Privacy Framework. Free und Pro sind für den professionellen Einsatz ungeeignet.
Welche KI-Tools sind im Unternehmen erlaubt?
Erlaubt ist, was vertraglich, technisch und prozessual abgesichert werden kann. Konkret: AVV mit dem Anbieter, wirksame Drittlandtransfer-Grundlage, Tarif ohne Trainingszugriff auf Kundendaten, dokumentierte Sub-Processor und eine interne Nutzungsrichtlinie. Für KI-Coding-Tools heißt das: Enterprise- oder Business-Tier statt Free, klare Regeln für Prompt-Inhalte, verbindlicher Review-Prozess.
Brauche ich für jeden KI-Tool-Einsatz eine DSFA?
Nein, nur wenn voraussichtlich ein hohes Risiko für die Rechte und Freiheiten betroffener Personen besteht (Artikel 35 DSGVO). Im klassischen Coding-Alltag ohne Personenbezug in Prompts und Codebase ist das selten. Sobald Test-Daten echte Kundendaten enthalten oder Logfiles in Prompts landen, ist eine DSFA fällig.
Was passiert, wenn die KI-Kompetenz-Pflicht nach Artikel 4 nicht erfüllt ist?
Direkte Bußgelder allein für die fehlende KI-Kompetenz sind im Sanktionskatalog des AI Act nicht explizit vorgesehen. Im Zusammenhang mit anderen Verstößen — etwa fehlender menschlicher Aufsicht oder Datenschutzpannen — wird die fehlende Schulung aber als verschärfender Umstand gewertet. Aufsichtsbehörden fragen sie inzwischen aktiv ab.
Reicht der EU-US Data Privacy Framework als Drittlandtransfer-Grundlage?
Für die meisten praktischen Fälle ja. Das DPF ist seit Juli 2023 wieder anerkannt, und die großen Anbieter (GitHub, Anthropic, OpenAI) haben sich zertifiziert. Wer maximale Absicherung will, kombiniert DPF mit Standardvertragsklauseln — das ist redundant, aber rechtlich am robustesten.
Wenn ihr im Team gerade die KI-Tool-Policy entscheidet, vor dem 2. August 2026 Klarheit über Anbieter-vs-Betreiber-Status braucht oder eure Schulung nach Artikel 4 noch nicht steht: 15 Minuten Erstgespräch — kostenfrei, ohne Folgepflicht. Was wir machen, steht unter Trainings.