Blog
GitHub Copilot wechselt zu AI Credits — was Entwickler ab Juni 2026 anders machen sollten
Kurz und scharf
Ab 1. Juni 2026 rechnet GitHub Copilot über AI Credits ab. 1 Credit = 0,01 USD. Die Listenpreise bleiben (Business 19, Enterprise und Pro+ 39 USD), aber das enthaltene Budget verbraucht sich tokenbasiert — Input, Output und Cache, jedes Modell mit eigenem Tarif. Spitzenmodelle wie GPT-5.5 oder Claude Opus 4.7 fressen das Budget bei agentischen Workflows in wenigen Tagen. Kein automatischer Fallback auf billige Modelle mehr.
Die Umstellung ist nicht überraschend. Wer im letzten halben Jahr ernsthaft mit Agenten gearbeitet hat — egal ob in Copilot, Claude Code oder Codex —, hat gespürt, dass das alte Premium-Request-Modell nicht mehr trägt. Eine "Anfrage" konnte 5.000 Tokens Kontext bedeuten oder 200.000. Beides für denselben Preis abrechnen war auf Dauer Unsinn. Mit dem 1. Juni 2026 zieht GitHub die Konsequenz und führt für alle bezahlten Tarife eine tokenbasierte Abrechnung ein.
Was sich konkret ändert
Jeder Tarif bekommt ab Juni ein monatliches Credit-Kontingent in Höhe des Listenpreises. Business-Nutzer haben damit 1.900 Credits pro Sitz und Monat, Enterprise-Nutzer 3.900. Verbraucht wird über Token, gerechnet zu den Listenpreisen der jeweiligen Modell-API — Input, Output und Cache fließen separat ein. Die offizielle Modellpreisliste zeigt, wie weit die Spreizung geht: GPT-5.4 nano kostet 1,25 USD pro Million Output-Tokens, GPT-5.5 30 USD, Claude Opus 4.7 25 USD, Gemini 3.1 Pro 12 USD. Faktor 24 zwischen günstigstem und teuerstem Modell.
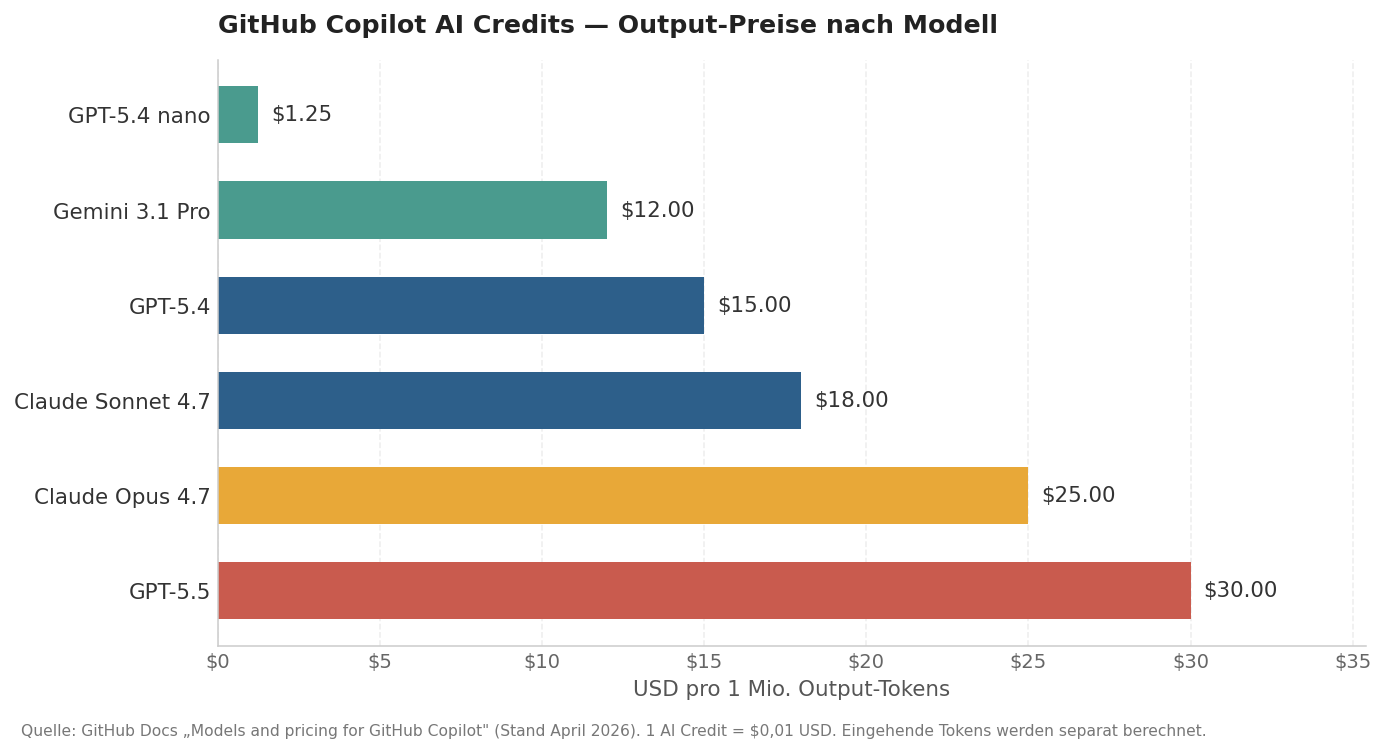
Was wegfällt, ist der bisherige Fallback. Bis Mai konnte ein Entwickler über sein Premium-Budget hinausgehen und landete dann automatisch auf GPT-5 mini, GPT-4.1 oder GPT-4o — ärgerlich, aber arbeitsfähig. Ab Juni gibt es das nicht mehr: Budget aufgebraucht heißt entweder Credits nachkaufen oder bis zum Monatsende pausieren. In der Community-Diskussion ist genau das der Punkt, an dem sich der größte Unmut entlädt.
Token-Math, die nach hinten losgehen kann
Ein Beispiel, das im Alltag schnell konkret wird. Ein Agent bekommt die Aufgabe, ein Modul in einem mittelgroßen Repository zu refactoren. Er liest acht Dateien, plant in einem Reasoning-Schritt, schreibt drei Dateien neu, lässt Tests laufen, korrigiert. Auf Claude Opus 4.7 sind das realistisch 80.000 Input-Tokens (mit Tool-Call-Replays), 12.000 Output-Tokens. Macht bei den aktuellen Listenpreisen rund 1,50 USD oder 150 Credits. Bei zwölf solcher Läufe an einem produktiven Tag ist das Business-Monatsbudget eines einzelnen Entwicklers in einer Woche weg.
Das gilt nicht für jede Art der Nutzung. Wer Copilot weiterhin primär für Inline-Completions verwendet, wird mit dem GPT-5.4-nano-Tarif lange auskommen. Eine durchschnittliche Tab-Completion bewegt sich im Bereich von ein paar hundert bis wenigen tausend Tokens, mit Cache-Hit oft im Cent-Bruchteil. Das ist der Grund, warum GitHub die Umstellung damit verkauft, dass sich für klassische Nutzung "nichts" ändert. Stimmt — solange man Agenten meidet.
Welches Modell wann
Die Praxis-Implikation ist, dass ab Juni eine bewusste Modell-Policy notwendig wird. Bisher war die Frage "welches Modell nehme ich" eher eine Geschmacksentscheidung; ab Juni ist sie eine Budget-Entscheidung. Eine sinnvolle Heuristik aus den Trainings, die ich gerade fahre, sieht ungefähr so aus: Inline-Completions und triviale Edits laufen auf dem günstigsten verfügbaren Modell, weil der Qualitätsunterschied minimal ist. Sobald ein Agent mit mehreren Tool-Calls oder repo-weitem Kontext arbeitet, lohnt sich das stärkere Modell — aber nur dann. Architektur-Refactorings, sicherheitskritische Reviews und Test-Generation für komplexe Domänen sind die einzigen Stellen, an denen Opus 4.7 oder GPT-5.5 wirklich überzeugen. Alles dazwischen ist meistens Verschwendung.
Caching wird zum harten Hebel. Anthropic und OpenAI rechnen Cache-Reads deutlich günstiger ab als frische Inputs — typischerweise mit Faktor 5 bis 10. Wer seine Prompt-Strukturen so baut, dass System-Prompts, Repository-Kontext und stabile Anweisungen am Anfang stehen und sich nur die Aufgabe am Ende ändert, halbiert die Kosten. Das ist keine neue Best Practice, war aber bisher ein Nice-to-have. Ab Juni ist es ein Muss.
Was Teams jetzt im Mai tun sollten
GitHub schaltet ab Mai eine Vorschau in der Abrechnungsansicht frei, die zeigt, wie die Nutzung der letzten Monate nach neuem Modell aussieht. Diese Preview ist die einzige verlässliche Datengrundlage, weil sie Cache-Treffer und tatsächliche Modellwahl berücksichtigt. Wer das in einem mittelgroßen Team nicht im Mai prüft, fährt im Juni blind.
Die zweite Aufgabe: eine interne Modell-Default-Konfiguration. Copilot lässt seit der 2025er Welle das Festlegen eines Default-Modells pro Organisation zu. Wer die Wahl den Entwicklern überlässt, bekommt entweder Mut-Sparen oder genau das Gegenteil — beides nicht produktiv. Eine simple Regel ("Default GPT-5.4, Opus nur bei explizitem Agent-Run mit mehr als drei Dateien") ist meist genug.
Drittens lohnt sich ein kurzer Blick auf Annual-Verträge. Bestehende Jahrespläne bleiben bis zum Ende der Laufzeit im alten Premium-Request-Modell, aber GitHub berechnet einen Multiplikator für teurere Modelle. Wer auf Annual umsteigen wollte, um Geld zu sparen, sollte das Modell genau anschauen — die Rechnung kann sich umkehren.
Einordnung
Aus Engineering-Sicht ist die Umstellung fair. Premium-Requests waren nie ein gutes Maß für tatsächlichen Verbrauch, und die Anbieter mussten Token-basiert abrechnen, sobald Agenten zum Mainstream wurden. Anthropic hat testweise Claude Code aus den Pro-Tarifen genommen, Cursor experimentiert mit eigenen Credit-Modellen — die Branche bewegt sich gleichgerichtet. Der Schmerzpunkt liegt nicht im Mechanismus, sondern in der fehlenden Sichtbarkeit. Solange Entwickler nicht in Echtzeit sehen, was ein Prompt kostet, ist Selbstkontrolle schwierig. Die Preview ab Mai hilft, ist aber nicht das gleiche wie ein Live-Counter im IDE-Statusbar — und genau das fehlt aktuell noch.
Für Teams, die Copilot ernsthaft einsetzen, ist die wichtigste Botschaft nicht, ob die Umstellung gerecht ist, sondern dass die Nutzung ab Juni messbar wird. Wer agentische Workflows so baut, dass sie effizient mit Tokens umgehen, gewinnt. Wer Agenten als unbegrenzte Ressource behandelt hat, bekommt im Juli die Rechnung — wörtlich.
Wenn ihr im Team gerade entscheidet, wie ihr Copilot ab Juni einsetzt, oder unsicher seid, wo agentische Workflows in eurem Stack wirklich Sinn ergeben: 15 Minuten Erstgespräch — kostenfrei, ohne Folgepflicht. Was wir machen, steht unter Trainings.