Blog
Warum ein KI Entwickler Kurs 2026 anders aussehen muss als ein Tool-Tutorial
Letzte Woche hat mir ein Engineering Manager bei einem Automotive-Kunden gesagt: “Wir haben Copilot seit acht Monaten ausgerollt. Die Hälfte meiner Leute nutzt es täglich, die andere Hälfte hat es wieder abgeschaltet. Und ich habe keine Ahnung, wer von beiden recht hat.” Dieser Satz fasst ziemlich gut zusammen, wo die meisten Enterprise-Teams gerade stehen — irgendwo zwischen Euphorie und Ernüchterung, ohne klare Orientierung.
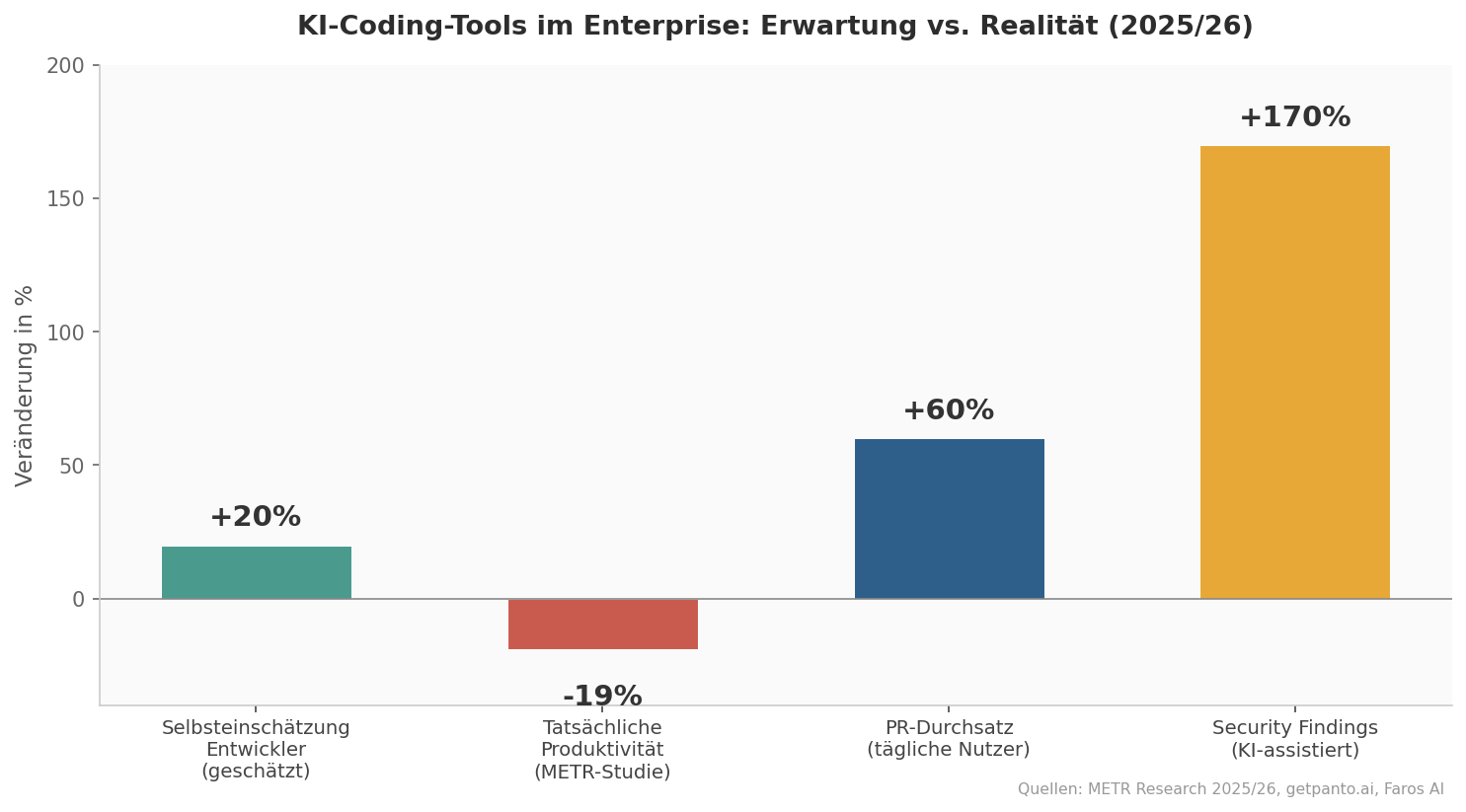
Die Zahlen bestätigen das. METR, ein unabhängiges Forschungsinstitut, hat Anfang 2025 sechzehn erfahrene Open-Source-Entwickler untersucht — Leute mit jahrelanger Erfahrung an Repositories mit über 22.000 Stars und mehr als einer Million Zeilen Code. Das Ergebnis hat die Beteiligten selbst überrascht: Mit KI-Tools brauchten sie im Schnitt 19 Prozent länger für ihre Aufgaben. Gleichzeitig schätzten dieselben Entwickler, dass sie 20 Prozent schneller gewesen seien. Die Wahrnehmung und die Wirklichkeit laufen auseinander.
Das Problem liegt nicht in den Tools. Cursor, Claude Code, GitHub Copilot — sie alle sind technisch beeindruckend. Das Problem liegt darin, wie Teams sie einsetzen. Und genau hier trennt sich ein brauchbarer KI Entwickler Kurs von einer Cursor-Schnellanleitung.
Es geht nicht um das Tool. Es geht um den Workflow.
Ich beobachte seit über zwei Jahren, wie Enterprise-Teams KI-Tools einführen. Das Muster wiederholt sich: Jemand aus dem Team entdeckt Cursor oder Claude Code, ist begeistert, zeigt es den Kollegen. Drei Wochen später nutzen es fünf Leute — jeder anders. Einer lässt sich ganze Klassen generieren, eine andere nutzt es nur für Docstrings, ein dritter hat es stillschweigend wieder deinstalliert, weil der generierte Code seinen Review nicht überlebt hat.
Was fehlt, ist kein Wissen über Tastenkürzel oder Prompt-Tricks. Was fehlt, ist ein gemeinsames Verständnis dafür, an welchen Stellen im Entwicklungsprozess KI tatsächlich Wert erzeugt — und an welchen sie Schaden anrichtet, wenn man sie unkontrolliert loslässt.
Ein konkretes Beispiel: Eine Finanzdienstleistungs-Firma, mit der wir gearbeitet haben, hatte KI-assistierten Code in ihrer Pipeline. Der PR-Durchsatz stieg um knapp 40 Prozent. Klingt gut. Gleichzeitig verdreifachten sich die Security Findings im SAST-Scanner, und die Hotfix-Rate nach Deployments ging nach oben. Der Netto-Effekt war negativ — mehr Code, aber auch mehr Probleme, die nachgelagert Zeit kosteten. Das deckt sich mit Branchendaten: KI-assistierte Teams produzieren im Durchschnitt 1,7-mal so viele Issues und verschiffen deutlich mehr Security Findings, wenn keine Governance-Strukturen greifen.
Wo KI im Enterprise-Alltag tatsächlich funktioniert
Die Stellen, an denen KI-Tools heute wirklich produktiv sind, liegen selten dort, wo die Marketing-Demos sie zeigen — nicht beim Generieren einer kompletten React-Komponente aus einem Einzeiler-Prompt, sondern im weniger glamourösen Teil der Softwareentwicklung, dem Teil, der 60 bis 70 Prozent der Arbeitszeit ausmacht, den aber niemand auf einer Konferenzbühne vorzeigt.
Testing ist der stärkste Hebel. Wer KI-Tools nutzt, um aus bestehendem Produktionscode Unit-Tests zu generieren, Randfall-Szenarien zu identifizieren und Regressionstests für Legacy-Systeme zu schreiben, der sieht messbare Ergebnisse. Die generierten Tests sind beim ersten Durchlauf selten produktionsreif — aber darum geht es nicht. Der entscheidende Gewinn liegt darin, dass der Zeitaufwand für den Einstieg in eine Testabdeckung dramatisch sinkt. Ein Modul, für das ein Entwickler normalerweise zwei Tage braucht um die erste sinnvolle Testsuite zu schreiben, hat nach einer halben Stunde mit KI-Unterstützung eine Rohfassung, die man in eine Stunde auf Produktionsniveau bringt.
CI/CD-Pipeline-Integration ist der zweite Bereich, der unterschätzt wird. KI-Tools können nicht nur Code schreiben, sie können auch Konfigurationen generieren, Pipeline-Stages entwerfen und Infrastructure-as-Code-Templates erstellen. Der Punkt ist: Das funktioniert nur, wenn der Entwickler weiß, was die Pipeline tun soll. Wer die Architektur nicht versteht, bekommt von Claude Code eine technisch korrekte, aber fachlich unsinnige GitHub-Actions-Konfiguration.
Code-Review und Refactoring sind der dritte Bereich. Bestehenden Code analysieren, Abhängigkeiten verstehen, Verbesserungsvorschläge formulieren — hier arbeiten KI-Tools erstaunlich zuverlässig, weil sie auf einen begrenzten, konkreten Kontext zugreifen. Das ist das Gegenteil der Greenfield-Situation, in der ein LLM frei halluzinieren kann. Bei einem Review hat es eine klare Referenz, gegen die es argumentieren muss.
Vibe Coding ist das Gegenteil von dem, was Enterprise braucht
Der Begriff “Vibe Coding” hat sich 2025 verbreitet — man gibt dem Tool eine vage Beschreibung, lässt es Code generieren, probiert aus ob es funktioniert, iteriert per Trial-and-Error. Für ein persönliches Hobbyprojekt oder einen schnellen Prototypen funktioniert das oft gut genug. Aber für einen Finanzdienstleister mit regulatorischen Anforderungen, eine Automotive-Firma mit ASIL-Normen oder ein Healthcare-Unternehmen mit IEC 62304 ist es schlicht nicht tragbar.
Vibe Coding setzt voraus, dass man das Ergebnis nicht verstehen muss — nur ob es funktioniert. In einem Enterprise-Kontext ist das gefährlich. Code, den niemand im Team nachvollziehen kann, ist technische Schuld vom ersten Commit an. Er lässt sich nicht sinnvoll reviewen, nicht gezielt debuggen und nicht verantwortungsvoll weiterentwickeln.
Was Enterprise-Teams stattdessen brauchen, ist das genaue Gegenteil: einen kontrollierten, nachvollziehbaren Einsatz von KI-Tools innerhalb bestehender Qualitätsprozesse. Das bedeutet klare Regeln dafür, wann ein Entwickler KI-generierten Code committen darf, wie Reviews für solchen Code ablaufen und welche automatisierten Checks in der Pipeline greifen müssen, bevor irgendetwas in die Produktion geht.
Warum ein guter KI Entwickler Kurs Expertenwissen braucht
Hier kommen wir zum eigentlichen Punkt. Die meisten Angebote, die unter “KI Entwickler Kurs” laufen, sind Tool-Tutorials: So installierst du Cursor, so schreibst du einen Prompt, hier sind zehn Tricks für GitHub Copilot. Das ist in etwa so hilfreich wie ein Kurs “Schraubenschlüssel für Anfänger” für jemanden, der ein Auto reparieren soll.
Ein Kurs, der Enterprise-Teams wirklich weiterbringt, muss Dinge leisten, die ein YouTube-Tutorial oder eine offizielle Dokumentation nicht abdecken können.
Das fängt bei der Codebase an. Ein generisches Todo-App-Beispiel ist irrelevant, wenn euer Team mit einem 15 Jahre alten Java-Monolithen kämpft oder mit einer Microservice-Architektur, bei der jeder Service andere Konventionen hat. Die Frage ist nicht “Kann Claude Code eine Funktion schreiben?” — die Frage ist “Kann Claude Code eine Funktion schreiben, die in unsere Architektur passt, unsere Naming Conventions befolgt und unseren Review-Prozess übersteht?” Wer diese Frage mit einem Standard-Kursbeispiel beantworten will, hat das Problem nicht verstanden.
Genauso entscheidend ist, wer vor dem Team steht. Nicht Trainer, die seit drei Monaten KI-Tools ausprobieren — sondern Entwickler, die wissen, wie es sich anfühlt, wenn ein KI-generierter Fix den Integration-Test in einer Umgebung mit zwanzig Microservices zerschießt. Was funktioniert in Legacy-Systemen, wo liegen die Fallstricke bei reguliertem Code, wie baut man KI-Testing in eine bestehende Pipeline ein: Dieses Erfahrungswissen lässt sich nicht aus einer Dokumentation ablesen. Es entsteht durch Jahre an produktivem Enterprise-Code.
Und am Ende muss sich der Workflow verändern, nicht nur das Tooling. Nach einem guten KI Entwickler Kurs hat ein Team nicht bloß gelernt, welche Buttons man drücken muss. Es hat gemeinsame Regeln für KI-Nutzung, angepasste Review-Prozesse, integrierte Quality Gates in der Pipeline und ein realistisches Bild davon, wo KI hilft und wo man besser die Finger davon lässt.
Was sich für Entscheider verändert
Für Teamleiter und Engineering Manager stellt sich die Frage anders als für individuelle Entwickler. Es geht nicht darum, ob KI-Tools “cool” sind. Es geht darum, ob das Investment in Lizenzen und Schulung sich in messbaren Ergebnissen niederschlägt — weniger Bugs, schnellere Releases, höhere Testabdeckung. Und es geht um die Frage, ob man das Risiko kontrolliert bekommt: Security-Bedenken, Compliance-Anforderungen, Intellectual-Property-Fragen.
Ein KI Entwickler Kurs, der diese Fragen ignoriert und stattdessen zwei Tage Prompt Engineering anbietet, verfehlt das Ziel. Die Technologie ist da. Was fehlt, ist die Methodik, um sie in bestehende Strukturen einzubetten, ohne dabei die Code-Qualität zu opfern.
Die 50 Prozent der Teams, die KI-Tools wieder abschalten, tun das nicht, weil die Tools schlecht sind. Sie tun es, weil niemand ihnen gezeigt hat, wie man sie richtig einsetzt — mit Struktur, mit Governance und mit einem klaren Blick dafür, was man von einem Sprachmodell erwarten kann und was nicht.
Die Autoren von no-vibes() entwickeln seit über 15 Jahren aktiv im Enterprise-Umfeld — in Branchen wie Automotive, Finance und Healthcare. Sie beschäftigen sich nicht nur theoretisch mit Workflows, Pipelines und Use Cases, sondern erproben verschiedene Ansätze systematisch im Entwickler-Alltag und geben diese Erfahrungen in Trainings weiter.
Euer Team schneller mit KI-Tools machen?
Keine Hype-Trainings, sondern echte Techniken die funktionieren.
Erstgespräch buchen →