Blog
KI Programmierung lernen: Warum erfahrene Entwickler diesmal nicht einfach loslegen sollten
Erfahrene Entwickler sind es gewohnt, sich neue Technologien selbst beizubringen. Neues Framework? Dokumentation lesen, ein Prototyp bauen, in zwei Wochen produktiv. Neue Sprache? Ähnliches Muster. Die meisten Seniors, die ich kenne, haben sich genau so durch zwanzig Jahre Technologiewandel gearbeitet — und zwar gut. Deshalb ist der erste Instinkt bei KI-Coding-Tools derselbe: installieren, ausprobieren, learning by doing. Und genau dieser Instinkt führt diesmal in eine Sackgasse, die man erst nach Wochen bemerkt.
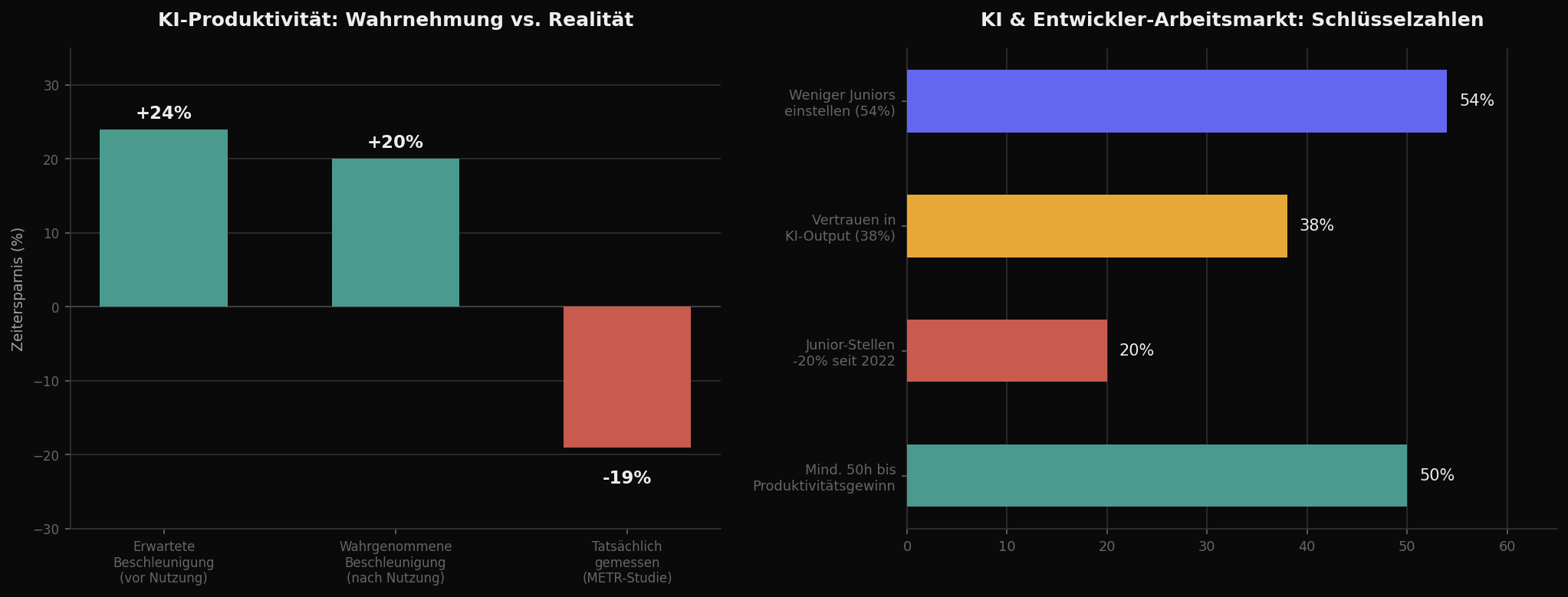
Die METR-Studie von 2025, eine der methodisch saubersten Untersuchungen zum Thema, hat eine Zahl produziert, die in der Branche für Unruhe gesorgt hat: Erfahrene Open-Source-Entwickler waren mit KI-Tools im Schnitt 19 Prozent langsamer als ohne. Nicht schneller. Langsamer. Und das Irritierende daran: Die Entwickler selbst schätzten, dass sie 20 Prozent schneller geworden seien. Vor dem Experiment hatten sie sogar eine Beschleunigung von 24 Prozent erwartet. Die Diskrepanz zwischen Gefühl und Messung ist enorm — und sie erklärt, warum so viele Teams nach Monaten mit KI-Tools frustriert sind, ohne genau benennen zu können, woran es liegt.
Warum der übliche Weg diesmal nicht funktioniert
Wenn ein erfahrener Java-Entwickler Kotlin lernt, überträgt er 80 Prozent seines Wissens direkt. Die Konzepte sind die gleichen, die Syntax ist anders. Genau deshalb funktioniert Dokumentation plus Ausprobieren so gut — das Delta zwischen dem, was man weiß, und dem, was man lernen muss, ist überschaubar und klar abgegrenzt.
Bei KI-Programmierung ist dieses Delta anders beschaffen. Die Schwierigkeit liegt nicht in der Bedienung der Tools. Einen Prompt schreiben, Tab drücken, Vorschlag akzeptieren — das kann jeder nach zehn Minuten. Die Schwierigkeit liegt darin, dass KI-assistiertes Arbeiten das Verhältnis zwischen Schreiben und Bewerten grundlegend verschiebt. Statt Code zu produzieren, reviewt man Code. Statt Architekturentscheidungen explizit zu treffen, muss man sie in KI-generiertem Output erkennen und korrigieren. Das sind andere kognitive Anforderungen, und sie erfordern andere Gewohnheiten — nicht andere Syntax.
Ein Udemy-Kurs hilft hier wenig, weil er typischerweise die Werkzeugbedienung lehrt: Hier ist das Tool, hier sind die Features, hier ein Beispielprojekt. Was er nicht lehrt, ist die Frage, die erfahrene Entwickler tatsächlich umtreibt: Wo in meinem konkreten Arbeitsalltag bringt KI einen echten Hebel, und wo erzeugt sie nur die Illusion von Geschwindigkeit? Diese Frage lässt sich nicht mit einem generischen Kurs beantworten, weil die Antwort von der Codebasis abhängt, von der Teamstruktur, von den Compliance-Anforderungen, von der Art der Aufgaben, die das Team täglich bearbeitet.
Learning by doing hat ein anderes Problem. KI-Tools geben ständig Feedback — aber es ist das falsche Feedback. Das Tool liefert schnell einen Vorschlag, der auf den ersten Blick plausibel aussieht. Man akzeptiert ihn, arbeitet weiter, und es fühlt sich produktiv an. Erst im Review, in der Pipeline oder drei Wochen später im Bugtracker zeigt sich, dass der generierte Code subtile Probleme hat. Ohne jemanden, der einem zeigt, worauf man achten muss, baut man sich Muster an, die schwer wieder abzutrainieren sind. Die Studie der Stanford Digital Economy Group hat genau das gemessen: Teams ohne klare KI-Governance produzierten deutlich mehr Issues und Security Findings.
Was ein guter Kurs anders macht
Ich sage das als jemand, der selbst jahrelang davon überzeugt war, dass externe Trainings für erfahrene Entwickler Zeitverschwendung sind. Für die meisten Technologien stimmt das auch. Aber KI Programmierung lernen hat eine Eigenschaft, die es von Framework- oder Sprachwechseln unterscheidet: Die Lernkurve ist nicht linear, sondern konterintuitiv. Man wird zunächst schlechter, bevor man besser wird — und ohne Orientierung merkt man das nicht einmal.
Ein guter Kurs für erfahrene Entwickler unterscheidet sich grundlegend von dem, was die meisten Plattformen anbieten. Er fängt nicht bei null an und erklärt nicht, was ein Prompt ist. Stattdessen arbeitet er mit dem Code der Teilnehmer, mit ihren Repositories und ihren tatsächlichen Aufgaben. Er zeigt nicht nur, wie man KI-Tools bedient, sondern wo die Grenzen liegen — und zwar anhand konkreter Fehlermuster, die in Enterprise-Codebases regelmäßig auftreten.
Konkret lernt man in einem soliden KI-Entwicklertraining drei Dinge, die man sich allein nur schwer erarbeitet. Erstens: Aufgabenklassifikation. Nicht jede Entwickleraufgabe profitiert gleich stark von KI. Inline-Completions bei Boilerplate-Code? Hoher Hebel, niedriges Risiko. Agentisches Refactoring über Servicegrenzen? Hoher Hebel, aber auch hohes Risiko, wenn man die Ergebnisse nicht systematisch validiert. Die Fähigkeit, Aufgaben in diese Kategorien einzuteilen, bevor man KI einsetzt, macht den Unterschied zwischen dem Team, das nach drei Monaten produktiver ist, und dem Team, das nach drei Monaten ein Qualitätsproblem hat.
Zweitens: Review-Patterns für KI-generierten Code. Der Review von Code, den ein Mensch geschrieben hat, folgt anderen Mustern als der Review von Code, den ein KI-Agent generiert hat. Menschen machen bestimmte Fehler konsistent — man kennt die Handschrift des Kollegen. KI-generierter Code sieht oft sauberer aus, hat aber andere typische Schwächen: inkonsistente Architekturentscheidungen über Dateigrenzen hinweg, halluzinierte API-Aufrufe, Security-Patterns, die auf den ersten Blick korrekt aussehen, aber subtile Lücken haben. Diese Muster zu kennen spart auf Dauer erheblich mehr Zeit, als das Tool selbst je einsparen kann.
Drittens: Integration in bestehende Prozesse. Wo setzt man Quality Gates, wenn ein Agent zwanzig Dateien auf einmal ändert? Wie dokumentiert man KI-assistierte Entscheidungen für ein Audit? Welche Team-Konventionen braucht man, wenn drei Entwickler dasselbe Tool unterschiedlich intensiv nutzen? Diese Fragen kommen in keinem Udemy-Kurs vor, weil sie keine Tool-Fragen sind — es sind Prozessfragen, und sie werden in Enterprise-Teams innerhalb von Wochen zur Quelle von Konflikten, wenn sie nicht von Anfang an adressiert werden.
Das heißere Thema: Programmieren lernen mit KI als Berufseinsteiger
Während erfahrene Entwickler diskutieren, wie sie KI in ihren Alltag integrieren, steht eine andere Gruppe vor einer grundsätzlicheren Frage: Soll ich Programmieren von Anfang an mit KI lernen — oder bewusst ohne? Es ist eine Frage, die gerade das Potenzial hat, eine Generation von Entwicklern in zwei Lager zu spalten.
Die Zahlen sind eindeutig unangenehm. Die Beschäftigung von Softwareentwicklern zwischen 22 und 25 Jahren ist laut einer Stanford-Studie seit Ende 2022 um fast 20 Prozent gesunken. Über die Hälfte der Engineering-Leiter plant, weniger Juniors einzustellen, weil Seniors mit KI-Unterstützung mehr abdecken können. Der Einstieg in die Branche wird schwerer, nicht leichter — und das obwohl die Nachfrage nach Software insgesamt steigt.
Die naheliegende Antwort lautet: Natürlich mit KI lernen, das ist die Realität, auf die man sich vorbereiten muss. Und in einem gewissen Rahmen stimmt das. KI-Tools können beim Lernen helfen, sie können Fehler erklären, Konzepte illustrieren, und sie können den frustrierenden Leer-Lauf reduzieren, der Anfänger zum Aufgeben bringt.
Aber es gibt eine Grenze, die schwer zu erkennen ist, wenn man sie noch nie überschritten hat. Universitätsstudien aus 2025 zeigen ein wiederkehrendes Muster: Studierende, die früh mit KI-Assistenz arbeiten, entwickeln ihr Codeverständnis schneller als frühere Jahrgänge — solange die KI verfügbar ist. Sobald sie ohne KI arbeiten müssen, bricht die Leistung ein, und zwar stärker als bei vergleichbaren Gruppen, die ohne KI gelernt haben. Die Studierenden haben gelernt, KI-Output zu lesen und zu verwenden, aber nicht, die darunterliegenden Konzepte selbstständig anzuwenden.
Regeln, die sich für Berufseinsteiger bewährt haben
Teams, die Juniors erfolgreich mit KI-Unterstützung ausbilden, arbeiten fast alle mit einer Variante derselben Grundregel: KI darf erklären, aber nicht ersetzen. Das klingt simpel, erfordert aber erstaunlich klare Abgrenzungen im Alltag.
Die erste Praxis, die sich durchgesetzt hat, ist die verzögerte KI-Nutzung. Neue Entwickler lösen eine Aufgabe zuerst ohne KI — auch wenn es länger dauert und frustrierend ist. Erst danach vergleichen sie ihre Lösung mit dem, was ein KI-Tool vorschlägt. Der Vergleich ist der eigentliche Lernmoment: Wo hat die KI eine bessere Lösung? Wo eine schlechtere? Warum? Dieser Prozess zwingt dazu, den KI-Output kritisch zu lesen, statt ihn einfach zu übernehmen.
Die zweite Praxis ist das Erklärungsprinzip. Jede KI-generierte Codezeile, die ein Junior in einen PR stellt, muss er oder sie erklären können — nicht dem Tool, sondern einem Menschen im Review. Wenn die Erklärung nicht kommt, wird der PR zurückgewiesen, unabhängig davon, ob der Code funktioniert. Das ist anfangs unbequem und verlangsamt den Output, aber es verhindert das gefährlichste Anti-Pattern: Code-Akzeptanz ohne Verständnis.
Die dritte Praxis betrifft die Tool-Rotation. Juniors sollten nicht monatelang ausschließlich mit einem KI-Tool arbeiten. Der Wechsel zwischen verschiedenen Ansätzen — mal Inline-Completion, mal Chat-basiert, mal agentisch, mal komplett ohne KI — verhindert, dass sich blinde Abhängigkeiten bilden. Es fördert ein Verständnis dafür, was das Tool tut und was man selbst tut, und genau diese Unterscheidung ist es, die langfristig einen kompetenten Entwickler von jemandem unterscheidet, der nur Prompts schreiben kann.
Die vierte und häufig unterschätzte Praxis ist Debugging ohne KI. Wenn ein Bug auftritt, sollte ein Junior zunächst selbst debuggen — Breakpoints setzen, Logs lesen, Hypothesen bilden. Erst wenn er eine Vermutung hat, darf die KI als Sparringspartner hinzukommen. Das klingt altmodisch, trainiert aber genau die Fähigkeit, die in den nächsten Jahren am wertvollsten sein wird: ein mentales Modell davon zu haben, wie Code tatsächlich ausgeführt wird.
Warum beides zusammengehört
Die Frage, wie erfahrene Entwickler KI Programmierung lernen, und die Frage, wie Berufseinsteiger Programmieren mit KI lernen, sind zwei Seiten desselben Problems. Beide Gruppen müssen verstehen, wo KI hilft und wo sie schadet. Beide müssen Routinen entwickeln, die über die reine Werkzeugbedienung hinausgehen. Und beide unterschätzen systematisch, wie viel bewusste Arbeit das erfordert.
Der Unterschied ist: Erfahrene Entwickler haben ein Fundament, auf dem sie aufbauen können. Sie wissen, wie guter Code aussieht, sie kennen Architekturmuster, sie haben ein Gespür für technische Schulden. Was ihnen fehlt, ist die Fähigkeit, dieses Wissen in eine neue Arbeitsweise zu übersetzen — und das ist es, was ein gezieltes Training leisten kann, das ein YouTube-Tutorial oder ein generischer Online-Kurs nicht leistet.
Berufseinsteiger haben dieses Fundament noch nicht. Für sie ist die Herausforderung größer, weil sie gleichzeitig die Grundlagen und den Umgang mit KI lernen müssen, ohne dass das eine das andere verdrängt. Wer hier keine klaren Regeln hat, trainiert sich Muster an, die später schwer zu korrigieren sind — und das in einem Arbeitsmarkt, der immer weniger Geduld für Entwickler hat, die nur mit KI-Unterstützung funktionieren.
Die Autoren von no-vibes() entwickeln seit über 15 Jahren aktiv im Enterprise-Umfeld — in Branchen wie Automotive, Finance und Healthcare. Sie beschäftigen sich nicht nur theoretisch mit Workflows, Pipelines und Use Cases, sondern erproben verschiedene Ansätze systematisch im Entwickler-Alltag und geben diese Erfahrungen in Trainings weiter.
KI Programmierung richtig lernen — im Team?
Praxisnahe Trainings für erfahrene Enterprise-Entwickler. Kein Anfängerkurs.
Erstgespräch buchen →