Blog
KI-unterstützte Entwicklung im Team einführen: Die Checkliste vor dem Rollout
In den meisten Teams, die ich berate, hat die KI-unterstützte Entwicklung längst begonnen — nur eben nicht offiziell. Zwei, drei Leute nutzen seit Monaten private Accounts. Einer hat sich den Editor-Fork installiert, eine andere arbeitet mit einem Terminal-Agenten. Die generierten Code-Schnipsel landen in PRs, ohne dass das Team eine gemeinsame Haltung dazu hat. Und dann kommt die Frage, meist vom Lead oder vom CTO: Sollen wir das jetzt für alle ausrollen?
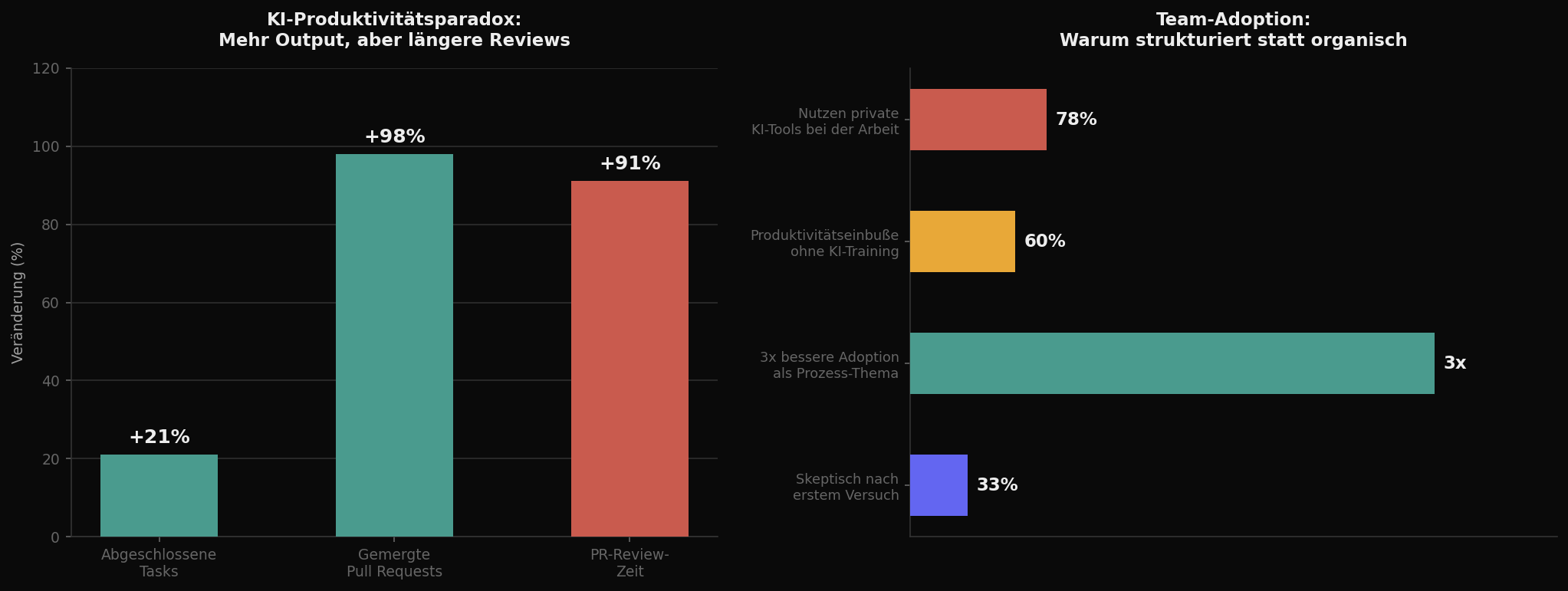
Die Antwort ist: Ja, aber nicht so. Nicht einfach Lizenzen kaufen und verteilen. Denn der Schritt vom einzelnen Entwickler, der privat experimentiert, zum Team, das KI-unterstützte Entwicklung als gemeinsamen Standard nutzt, ist kein Lizenzproblem. Es ist ein Prozessproblem. Und die Zahlen zeigen, warum das einen Unterschied macht: Teams, die KI-Einführung als Prozessthema behandeln, erreichen dreimal bessere Adoptionsraten als Teams, die einfach ein Tool bereitstellen.
Das Shadow-AI-Problem ernst nehmen
78 Prozent der Wissensarbeiter nutzen mittlerweile private KI-Tools bei der Arbeit — ohne Freigabe der IT, ohne Governance, ohne dass irgendjemand weiß, welche Daten wohin fließen. In Entwickler-Teams ist die Zahl vermutlich noch höher. Und das ist kein Zeichen von Ungehorsam, sondern von Pragmatismus: Die Tools sind gut genug, dass sie den Arbeitsalltag spürbar erleichtern, und die offizielle Einführung dauert zu lange.
Aber Shadow AI erzeugt Probleme, die schleichend wachsen. Wenn Entwickler A seinen Code mit einem KI-Agenten generiert und Entwickler B ohne KI reviewed, fehlt B der Kontext dafür, welche Art von Fehlern in KI-generiertem Code typisch sind. Die Review-Qualität sinkt, ohne dass es jemand merkt. Wenn drei Leute im Team drei verschiedene Tools mit drei verschiedenen Konfigurationen nutzen, entsteht eine Inkonsistenz in den Architekturentscheidungen, die erst Monate später als technische Schulden sichtbar wird. Und wenn sensible Codebases über private Accounts an externe KI-Dienste geschickt werden, hat das Unternehmen ein Compliance-Problem, von dem es möglicherweise erst im Audit erfährt.
Der erste Punkt auf der Checkliste ist deshalb nicht die Tool-Auswahl, sondern die Bestandsaufnahme: Wer im Team nutzt bereits was, in welcher Intensität, und mit welchen Daten? Diese Frage offen zu stellen — ohne Vorwurf, ohne Verbot — ist der einzige Weg, ein realistisches Bild zu bekommen. Alles andere baut auf einer Fiktion auf.
Bevor das Tool kommt: Die fünf Fragen, die jedes Team klären muss
Die Tool-Frage ist für die meisten Teams die einfachste. Schwieriger sind die Fragen, die sich nicht mit einer Lizenz beantworten lassen.
Frage 1: Was ist unser Review-Standard für KI-generierten Code? Das klingt trivial, ist es aber nicht. KI-generierter Code sieht anders aus als menschengeschriebener Code — oft sauberer auf der Oberfläche, aber mit subtilen Problemen darunter. Halluzinierte API-Aufrufe, inkonsistente Fehlerbehandlung über Dateigrenzen hinweg, Security-Patterns, die fast korrekt sind. Ein Team braucht eine gemeinsame Vereinbarung darüber, ob KI-generierter Code denselben Review-Prozess durchläuft wie manuell geschriebener Code, oder ob es zusätzliche Prüfschritte gibt. Meine Empfehlung: zusätzliche Prüfschritte, zumindest in den ersten drei Monaten. Nicht weil das Tool schlecht ist, sondern weil das Team lernen muss, die typischen Fehlermuster zu erkennen.
Frage 2: Welche Teile unserer Codebasis sind tabu? Nicht jeder Code eignet sich gleich gut für KI-Unterstützung. Sicherheitskritische Module, kryptographische Implementierungen, Datenbank-Migrationen mit Produktionsdaten, regulatorisch relevante Logik — in diesen Bereichen ist das Risiko von subtilen Fehlern überproportional hoch, und die Konsequenzen sind es auch. Ein Team sollte vor dem Rollout explizit definieren, wo KI-Tools eingesetzt werden dürfen und wo nicht. Das ist keine Angst vor Technologie, sondern ein nüchternes Risikomanagement.
Frage 3: Wie messen wir den Erfolg? Die naheliegende Metrik — Anzahl generierter Zeilen oder geschlossener Tickets — ist irreführend. Teams mit hoher KI-Adoption schließen zwar 21 Prozent mehr Tasks ab und mergen 98 Prozent mehr Pull Requests, aber die Review-Zeit steigt gleichzeitig um 91 Prozent. Wenn man nur die Output-Seite misst, sieht alles nach Erfolg aus. Wenn man die gesamte Pipeline betrachtet, entsteht ein differenzierteres Bild. Sinnvolle Metriken für die ersten Monate sind: Lead Time vom Commit bis zum Deployment, Anzahl der Bugs in KI-assistierten PRs im Vergleich zu manuellen, und die subjektive Zufriedenheit der Reviewer — nicht der Autoren.
Frage 4: Wer ist der interne Champion? Erfolgreiche KI-Einführungen haben fast immer einen oder zwei Leute im Team, die das Thema nicht nur befürworten, sondern aktiv vorleben. Nicht als Evangelisten, sondern als Praktiker, die in echten Code-Reviews zeigen, wie sie mit KI-Tools arbeiten, wo sie welches Tool einsetzen, und — das ist der wichtige Teil — wo sie bewusst darauf verzichten. Die Forschung nennt sie Local Champions, und sie sind effektiver als jede Top-Down-Schulung, weil sie den Kontext des eigenen Teams kennen.
Frage 5: Was passiert, wenn es nicht funktioniert? Etwa ein Drittel der Entwickler wird nach dem ersten Versuch skeptisch sein, weil die Ergebnisse hinter den Erwartungen zurückbleiben. Das ist normal und kein Grund, das Tool wieder abzuschalten. Aber es braucht einen Plan dafür. Wie lange gibt man dem Experiment Zeit? Welche Unterstützung bekommen Skeptiker? Und ab welchem Punkt entscheidet das Team, dass ein bestimmtes Tool nicht zum eigenen Workflow passt? Ohne diese Klarheit wird aus Skepsis schnell passiver Widerstand — und der ist in Entwickler-Teams besonders hartnäckig, weil er sich hinter legitimen technischen Argumenten verstecken kann.
Die Pipeline anpassen, bevor man den Output verdreifacht
Hier liegt der Fehler, den die meisten Teams machen. Sie geben ihren Entwicklern KI-Tools, die den Output verdreifachen, aber die Pipeline dahinter — Reviews, Tests, Deployments — bleibt unverändert. Das Ergebnis ist vorhersehbar: Der Flaschenhals verlagert sich. Statt langsam Code zu schreiben und schnell zu deployen, schreibt man jetzt schnell und wartet auf Reviews.
Die CI/CD-Pipeline braucht vor dem KI-Rollout mindestens drei Anpassungen. Erstens: automatisierte Quality Gates, die typische KI-Fehlermuster abfangen. Linter-Regeln für inkonsistente Error-Handling-Patterns, Security-Scanner, die halluzinierte Dependencies erkennen, und — bei agentischen Tools — Checks, die sicherstellen, dass Änderungen innerhalb der definierten Boundaries bleiben. Zweitens: eine Testabdeckung, die dem erhöhten Output standhält. Wenn ein Entwickler mit KI-Unterstützung dreimal so viele PRs pro Woche stellt, braucht die Testsuite eine Qualität, die das auffängt, was im Review durchrutscht. Drittens: ein angepasster Review-Prozess, der nicht davon ausgeht, dass ein einzelner Reviewer drei Stunden am Tag mit KI-generierten PRs verbringt.
Ich habe Teams gesehen, die nach dem KI-Rollout ihre gesamte Review-Kapazität in PR-Reviews versenkt haben, weil der Output explodiert ist, ohne dass die Prozesse mitwachsen konnten. Nach zwei Monaten war das Team erschöpft, die Qualität rückläufig, und die Schuld lag — natürlich — bei der KI. Tatsächlich lag sie bei der fehlenden Vorbereitung.
Die ersten 90 Tage: Was realistisch erreichbar ist
Organisationen, die KI-unterstützte Entwicklung erfolgreich einführen, arbeiten fast alle mit einem 90-Tage-Rhythmus, der drei Phasen umfasst.
In den ersten 30 Tagen geht es um Transparenz. Bestandsaufnahme der bestehenden Tool-Nutzung, Definition der Review-Standards, Identifikation der Champions im Team, und eine ehrliche Diskussion darüber, welche Erwartungen realistisch sind. Kein Produktivitätsgewinn in diesem Monat — das ist normal und muss kommuniziert werden, damit niemand nach zwei Wochen enttäuscht die Lizenz kündigt.
In den Tagen 31 bis 60 folgt die Kalibrierung. Das Team arbeitet mit dem gewählten Tool, sammelt konkrete Erfahrungen und passt die Regeln an. Welche Review-Checks funktionieren, welche erzeugen nur Reibung? Welche Codebasis-Bereiche eignen sich besser als erwartet, welche schlechter? Die Metriken aus Frage 3 werden zum ersten Mal ausgewertet, aber noch nicht bewertet — die Datenbasis ist zu dünn für Schlussfolgerungen.
Ab Tag 61 beginnt die Skalierung. Die Regeln stehen, die Pipeline ist angepasst, das Team hat ein gemeinsames Verständnis davon, wo KI hilft und wo nicht. Jetzt lohnt es sich, über fortgeschrittene Szenarien nachzudenken: agentisches Arbeiten für größere Refactorings, Integration mit Ticket-Systemen, automatisierte Code-Dokumentation. Aber eben erst jetzt — nicht am ersten Tag.
Was Teams übersehen, die schon angefangen haben
Der häufigste Fehler bei Teams, in denen einzelne schon länger mit KI arbeiten, ist die Annahme, dass die Erfahrung der Einzelnen auf das Team übertragbar ist. Das ist sie nicht. Was für den erfahrenen Senior funktioniert, der seit einem Jahr einen Terminal-Agenten nutzt und seine eigenen Konventionen dafür entwickelt hat, passt nicht für den Mid-Level-Entwickler, der gerade erst anfängt. Die persönlichen Workflows der Early Adopter sind wertvoll als Inspiration, aber sie sind keine Team-Strategie.
Der zweite blinde Fleck: Wissensasymmetrie. Wenn drei von acht Leuten im Team seit Monaten mit KI arbeiten und fünf nicht, entsteht eine Kluft, die über die reine Tool-Bedienung hinausgeht. Die KI-Erfahrenen haben ein implizites Verständnis dafür, wann sie dem Output vertrauen und wann nicht. Dieses Verständnis fehlt den Neulingen, und es lässt sich nicht durch eine Confluence-Seite mit Tipps transferieren. Es braucht Pair Programming, gemeinsame Review-Sessions und die Bereitschaft der Early Adopter, ihre Fehler und Fehleinschätzungen offen zu teilen — nicht nur ihre Erfolge.
Am Ende ist die Einführung von KI-unterstützter Entwicklung im Team kein Technologieprojekt. Es ist ein Change-Projekt, bei dem das Werkzeug der einfachste Teil ist. Wer das versteht und die Checkliste vor dem Rollout abarbeitet, spart sich die schmerzhaften Monate, die Teams durchlaufen, die einfach Lizenzen verteilt haben und auf das Beste gehofft haben.
Die Autoren von no-vibes() entwickeln seit über 15 Jahren aktiv im Enterprise-Umfeld — in Branchen wie Automotive, Finance und Healthcare. Sie beschäftigen sich nicht nur theoretisch mit Workflows, Pipelines und Use Cases, sondern erproben verschiedene Ansätze systematisch im Entwickler-Alltag und geben diese Erfahrungen in Trainings weiter.
KI-unterstützte Entwicklung im Team einführen?
Wir begleiten Teams von der Bestandsaufnahme bis zur produktiven Nutzung.
Erstgespräch buchen →