Blog
Warum gute Entwickler mit KI unersetzlicher werden — nicht überflüssiger
Kurz zusammengefasst
KI-Coding-Tools übernehmen echte Arbeit — Boilerplate, Tests, Dokumentation. Das ersetzt keine Architekturentscheidungen, kein Security Reasoning, kein Debugging in komplexen Produktionssystemen. Was sich ändert: Entwickler schreiben weniger Code und verantworten mehr Code. Das braucht mehr technische Tiefe, nicht weniger. Der Weiterbildungsbedarf ist real und dringend — besonders für alle, die gerade in den Beruf starten.
Die Prognosen haben wir alle gehört. KI-Agents übernehmen Junior-Stellen, Devin läuft autonom durch GitHub-Issues, und irgendwo auf LinkedIn postet jemand stolz, wie er ein komplettes Backend "ohne eine Zeile selbst geschrieben" vibe-gecodet hat. Dann erschien im Juli 2025 die METR-Studie.
Ein randomisiertes Kontrollexperiment mit 16 erfahrenen Open-Source-Entwicklern, 246 echte Aufgaben aus realen Repos: mit KI-Tools waren diese Entwickler im Schnitt 19 % langsamer. Nicht schneller — langsamer. Nicht weil die Tools schlecht sind, sondern weil die Aufgaben komplex waren. Das Debuggen von KI-generiertem Code, das Steuern der Agents, das Verifizieren der Outputs kostet kognitive Arbeit die sich bei schwierigen Tasks nicht amortisiert.
Das ist kein Argument gegen KI-Tools. Es ist ein Argument dafür, zu verstehen wo sie funktionieren — und welche Entwickler-Kompetenz danach mehr gefragt ist, nicht weniger.
Was KI tatsächlich übernimmt — und das ist viel
Erst die ehrliche Einschätzung: Ein erheblicher Teil von dem was Entwickler täglich tun, kann KI inzwischen besser oder zumindest schneller. Boilerplate ist die offensichtlichste Kategorie — REST-Controller, DTOs, Datenbankzugriff für CRUD-Operationen, Config-Klassen, Interface-Implementierungen nach bekanntem Muster. Unit Tests für Funktionen mit klaren Ein- und Ausgaben. Dokumentationskommentare. Regex-Patterns. TypeScript-Type-Definitionen aus JSON-Samples.
Hinzu kommen Routineaufgaben die früher Stunden gekostet haben: CSV-Parser für einmalige Datenmigration, Konvertierungsscripts zwischen Formaten, einfache CLI-Tools. "Write me a Python script that..." ist heute eine Anfrage die Copilot oder Claude Code in 30 Sekunden beantwortet. Wer das wegdiskutiert, argumentiert nicht ehrlich.
Das ist gut. Diese Tätigkeiten haben selten wirkliches Verständnis aufgebaut, ihr Anteil am Alltag war zu groß, und ihr Verschwinden ist kein Verlust. Was ebenfalls zunimmt: KI als Erklärungswerkzeug. Code verstehen ist für Entwickler oft zeitaufwendiger als Code schreiben. "Erkläre mir diesen 800-Zeilen-Legacy-Service" ist eine Aufgabe die Sprachmodelle heute vergleichsweise zuverlässig lösen. Onboarding in fremde Codebases wird messbar schneller.
Die Grenzen dieser Kategorie sind aber bekannt. GitClear hat über mehrere Jahre beobachtet wie sich der Code von Teams mit Copilot-Nutzung verändert hat: Code Churn hat sich nahezu verdoppelt, von etwa 3 % auf 5,5 %. Code Churn — Code der kurz nach dem Schreiben wieder geändert werden muss — ist ein Indikator für schlechtes Design oder unverstandene Requirements. KI-Tools schreiben schnell technisch korrekten Code. Wer diesen Code nicht wirklich versteht, überarbeitet ihn häufiger. Der Produktivitätshebel ist real; er setzt aber voraus, dass jemand das Ergebnis einschätzen kann.
Wo KI heute und auf absehbare Zeit scheitert
Architekturentscheidungen sind keine Optimierungsaufgaben. Sie sind Abwägungen unter Unsicherheit: Wie viele Entwickler können dieses System betreiben? Was kostet die Infrastruktur in drei Jahren bei zehnfachem Traffic? Welche Compliance-Anforderungen kommen wahrscheinlich noch? Wie schwer ist es, diese Entscheidung rückgängig zu machen wenn sie falsch war?
Ein Sprachmodell das "Design a microservices architecture for our e-commerce platform" bekommt, liefert eine technisch korrekte Antwort. Es weiß nichts von eurem Team-Skill-Level, eurem AWS-Vertrag, dem CTO der Microservices hasst weil er sie 2019 an anderer Stelle falsch eingesetzt hat, oder der regulatorischen Anforderung dass bestimmte Kundendaten nicht außerhalb Europas verarbeitet werden dürfen. Diese Kontextualisierung ist Entwickler-Kompetenz. Sie ist nicht in Trainingsdaten.
Verteilte Systeme debuggen ist ein ähnliches Problem. Wenn eine Anfrage in einer Multi-Service-Architektur intermittierend mit 503 fehlschlägt, liegt die Fehlerursache in der Kombination aus Logs, Metrics, Code-Zustand, Deployment-History — und dem impliziten Wissen: "das haben wir nach dem letzten Kubernetes-Upgrade ein paarmal gesehen, wahrscheinlich..." Erfahrene Entwickler tragen diesen Kontext im Kopf. Kein Agent hat ihn.
Security Reasoning ist eine eigene Kategorie. KI-Tools erkennen SQL Injection und bekannte OWASP-Patterns zuverlässig. Was sie schlechter können: das Threat Modeling für ein neues Feature. "Wenn wir OAuth2 hier so implementieren — was kann ein Angreifer damit machen der unsere Partnerintegration kennt?" Das ist kein Muster-Matching. Das ist Systemdenken kombiniert mit Angreifer-Perspektive. Es gibt Tools die dabei unterstützen können; sie ersetzen aber nicht das Sicherheitsbewusstsein des Entwicklers der diese Entscheidung verantwortet.
Requirements-Interpretation ist der am meisten unterschätzte Bereich. Was ein Stakeholder sagt und was er meint, divergiert. Was im Ticket steht und was die Software tun soll, divergiert. Das Erkennen dieser Divergenz bevor sie in Code gegossen wird, spart mehr Zeit als jede KI-Unterstützung beim Schreiben. Diese Fähigkeit entsteht durch Erfahrung mit echten Projekten und echten Stakeholdern. Sie ist nicht generierbar.
SWE-bench ist der gängige Benchmark für AI-Coding-Agents. Aktuelle Top-Modelle lösen etwa 40–50 % der dortigen Aufgaben. Klingt nach viel — bis man versteht was auf SWE-bench steht: gut definierte, isolierbare Bugs in bekannten Open-Source-Projekten mit klaren Reproduktionsschritten. Das ist das einfachste Segment von Entwickler-Arbeit. Die schwierigen 50 % sind nicht knapp nicht gelöst, sie sind fundamental anderer Natur.
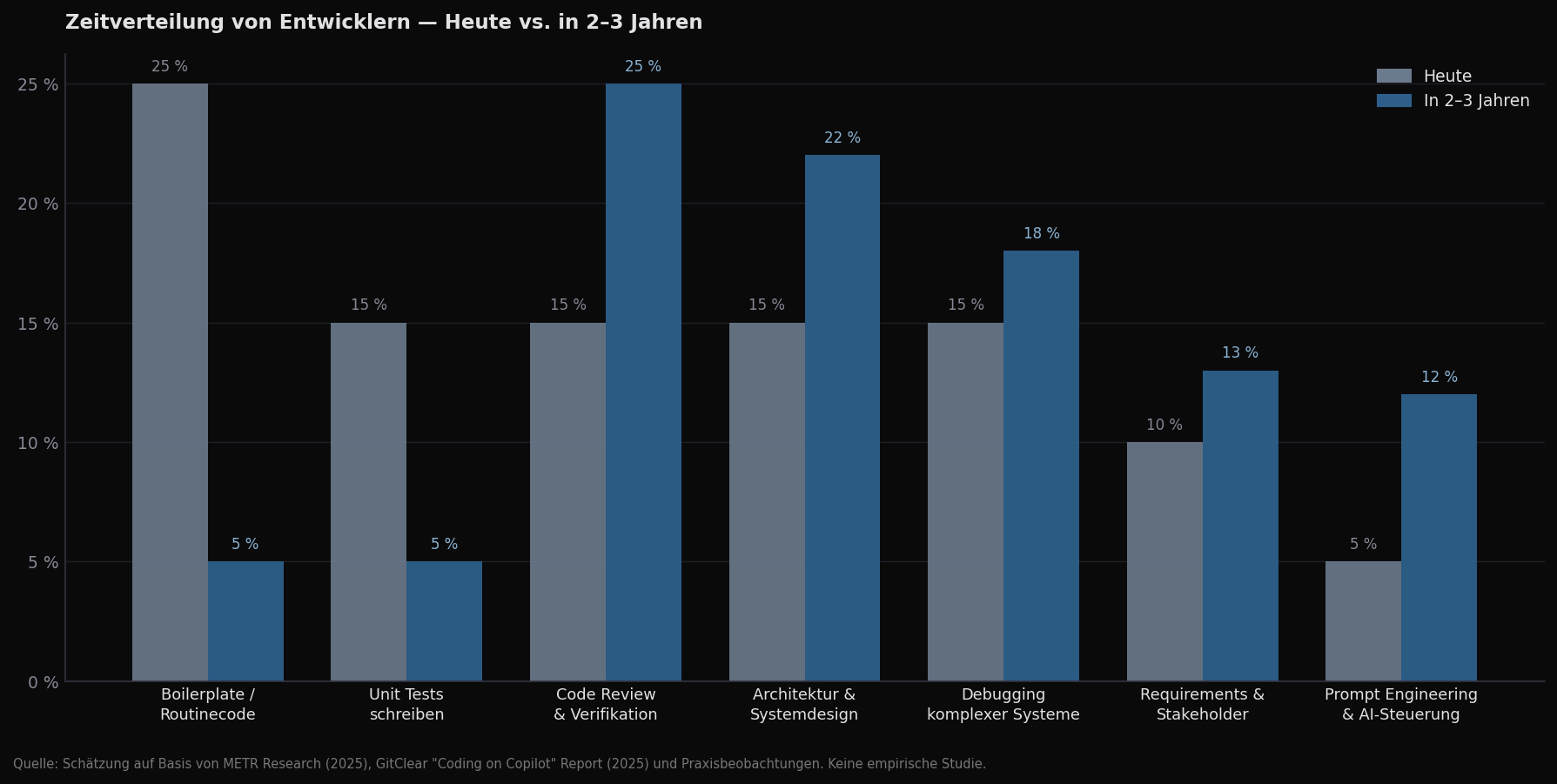
Wie sich der Arbeitsalltag verändert
Die Verschiebung läuft in eine Richtung: weniger schreiben, mehr steuern und verantworten.
Ein Entwickler der heute in einem gut aufgesetzten Team mit Cursor oder Claude Code arbeitet, schreibt schätzungsweise 40–60 % weniger Code als noch vor zwei Jahren. Dieser Code wird nicht einfach nicht geschrieben — er wird von einem Agent generiert, review-verpflichtet und dann deployed. Die Verantwortung für diesen Code liegt trotzdem beim Entwickler. Das klingt nach einer Formalität, ist aber keine.
Code verstehen ohne ihn geschrieben zu haben ist kognitiv anspruchsvoller als Code zu kennen den man selbst entwickelt hat. Entwickler brauchen mehr Review-Kapazität, mehr Sorgfalt beim Verifizieren von KI-Output, mehr Sicherheit im Einschätzen: "dieser Code ist korrekt — dieser Code ist riskant." Das erfordert tieferes, nicht weniger tiefes Technologieverständnis. Wer Architektur-Entscheidungen eines Agents nicht bewerten kann, deployt blindlings.
Prompt Engineering ist bereits Teil des Entwickler-Alltags in Teams die KI-Tools ernsthaft nutzen. Nicht im Sinn von "Hacks für bessere ChatGPT-Antworten", sondern als systematische Fähigkeit: Wie beschreibe ich eine Aufgabe so dass ein Coding-Agent sie korrekt löst? Wie strukturiere ich Kontext für ein Modell das die Codebase nicht vollständig kennt? Wie erkenne ich wenn der Output plausibel klingt aber falsch ist? Diese Fähigkeiten werden expliziter Teil der Jobbeschreibung.
Mehr Zeit für Architektur und Systemdesign ist die positive Kehrseite. Wenn Routine-Implementierung schneller geht, entsteht theoretisch Raum für die Arbeit die wirklich Unterschiede macht. Ob Teams diesen Freiraum für echte Qualitätsarbeit nutzen oder ihn mit schnellerer Feature-Delivery füllen, ist eine Managemententscheidung — aber das Potenzial ist real.
Der Weiterbildungsbedarf ist real — und die Zeit ist jetzt
Die vielleicht wichtigste Eigenschaft von KI-Coding-Tools ist: sie sind Multiplikatoren. Ein erfahrener Senior-Entwickler der versteht was er tut, der ein kritisches Auge für Code-Qualität hat, der Architektur gegen Business-Kontext abwägen kann — dieser Entwickler wird mit Cursor oder Claude Code messbar produktiver. Er delegiert richtig, reviewt sicher, erkennt wenn der Agent in die falsche Richtung läuft.
Ein Entwickler der das Fundament nicht hat — der nicht sicher genug ist um generierten Code kritisch zu bewerten, der keine internalisierte Intuition für Sicherheitsrisiken hat, der Architekturentscheidungen nicht begründen kann — dieser Entwickler wird gefährlich schnell. Nicht weniger produktiv: gefährlich schnell. Code der kompiliert und Tests besteht, aber falsch designed ist, ist teuer. Code der plausibel aussieht aber einen IDOR-Fehler oder eine unsachgemäße Autorisierungslogik hat, ist teuer. KI-Tools produzieren beides zuverlässig, wenn niemand das Ergebnis ernsthaft verifiziert.
Für die Karriereentwicklung hat das eine ernste Konsequenz. Juniors die heute ausschließlich KI-generiertem Code reviewen ohne jemals eigene Lösungen von Grund auf entwickelt zu haben, bauen kein tragfähiges Fundament auf. Sie bauen Abhängigkeit. Code lesen ohne Code geschrieben zu haben ist wie ein Buch lektorieren ohne je einen Satz selbst formuliert zu haben — man erkennt Fehler schlechter, hat kein Gefühl für den Aufwand, kann Qualität nicht einschätzen. Die Gefahr ist nicht Arbeitslosigkeit. Es ist eine Generation von Entwicklern die schnell Code deployen aber nicht verstehen was sie tun.
Das bedeutet nicht: Juniors sollten keine KI-Tools nutzen. Es bedeutet: Juniors müssen explizit lernen was KI ihnen nicht beibringt. Wie man ein System designed. Was Concurrency bedeutet. Warum bestimmte Muster in bestimmten Kontexten falsch sind. Dieser Lernpfad braucht heute mehr Bewusstsein, nicht weniger — weil die Tools ihn weniger sichtbar machen.
Die konkreten Fähigkeiten die mehr gefragt sein werden: Systemdesign und Architekturdenken, Security Reasoning und Threat Modeling, Testing-Strategie (nicht Test-Schreiben — das übernimmt KI), Debugging von komplexen verteilten Systemen, Requirements-Analyse und Stakeholder-Kommunikation. Das sind keine Neuigkeiten. Es sind die Fähigkeiten die gute Senior-Entwickler schon immer von mittelmäßigen getrennt haben. Der Unterschied ist: ohne diese Fähigkeiten kommt man in zwei Jahren nicht mehr durch das erste große Produktionsproblem — und zwar schneller als bisher, weil der KI-generierte Code das Problem vorher nicht sichtbar gemacht hat.
Wer diese Fähigkeiten nicht aktiv weiterentwickelt, wird nicht von KI ersetzt. Er wird von einem anderen Entwickler ersetzt, der KI und diese Fähigkeiten kombiniert.
Was das bedeutet
Diese Verschiebung ist keine theoretische Zukunft. Sie läuft gerade. Teams die KI-Tools produktiv einsetzen, berichten von gestiegenem Code-Volumen und gestiegenem Review-Aufwand. Von einem positiven Produktivitätsgefühl auf einfachen Aufgaben — weil der Hebel dort real ist. Und von einem steigenden Bedarf an Entwicklern die gut genug sind, das alles sicher zu steuern.
Der Beruf ändert sich. Das Fundament das ihn trägt — Systemverständnis, kritisches Urteilsvermögen, technische Tiefe — wird nicht ersetzt. Es wird sichtbarer, weil alles andere wegfällt das es früher verdeckt hat. Wer dieses Fundament hat und KI-Tools effektiv einsetzt, wird in drei Jahren Dinge bauen die heute noch nach Team-Arbeit klingen. Wer nur die Tools hat, wird Probleme bauen, die danach jemand anderes debuggen muss.
Quellen: METR Research (Juli 2025) — RCT mit 16 erfahrenen Open-Source-Entwicklern, 246 Tasks. GitClear "Coding on Copilot" Report (2024/2025) — Code Churn-Analyse über mehrere Jahre. SWE-bench Leaderboard (Stand Q1 2026). Praxisbeobachtungen aus Projekten 2024–2026.
KI-Skills aufbauen, die in Production tragen?
Kein Vibe Coding. Keine Tool-Demos. Systemverständnis, Review-Kompetenz, sichere KI-Integration im Team.
Erstgespräch buchen →